引言
设计目标
本项目的设计目标是从从传统宏内核与微内核出发, 改变内核功能模块的运行方式,由传统的函数调用方式转变为独立内核线程运行方式,内核线程拥有独立线程栈,发生失效时可通过微重启的方式恢复服务,不影响内核全局。
一般来说,将所有内核功能都集成在内核态的宏内核具有很好的性能,但是安全性和稳定性较差,内核中任何一个模块出现故障(一般为低质量的驱动代码)都会导致内核崩溃。微内核为了解决这个问题,将非核心的内核服务移动到用户态以独立的用户进程提供,但这也带来了频繁的进程间通信开销导致的性能问题。关于宏内核与微内核的更具体的讨论,可以参考内核架构一节。
本项目参考了以Windows-NT为代表的混合内核,综合宏内核和微内核的优点,尝试在增强内核服务可靠性的前提下尽量保证内核性能。具体来说,本项目:
-
采用基于内核线程服务模型的混合内核架构。(在 内核架构中详细说明)
-
基于Rust无栈异步协程机制和内核服务线程模型实现了一个多对多线程模型;
-
为了进行对比,实现了宏内核、混合内核两种内核对象,内核可以以两种架构模式运行;
-
直接实现Linux系统调用;
-
初步完成了对于musl-libc的支持,支持c语言应用程序(静态链接);
-
正在逐步完成对sqlite3, busybox等典型Linux应用程序的支持;
文档的说明
本文档主要说明内核设计中的主要思想和设计原则,以逐步揭示内核的整个架构和运行过程,必要时会讨论内核数据结构的设计,但不会对所有代码进行详细说明。
在本文档中,我们将我们实现的内核称为nCore。
内核架构分析
本章首先简要介绍传统操作系统宏内核和微内核架构的设计理念和优劣,再介绍本项目采用的混合内核架构设计。
下图显示了不同内核架构的区别。
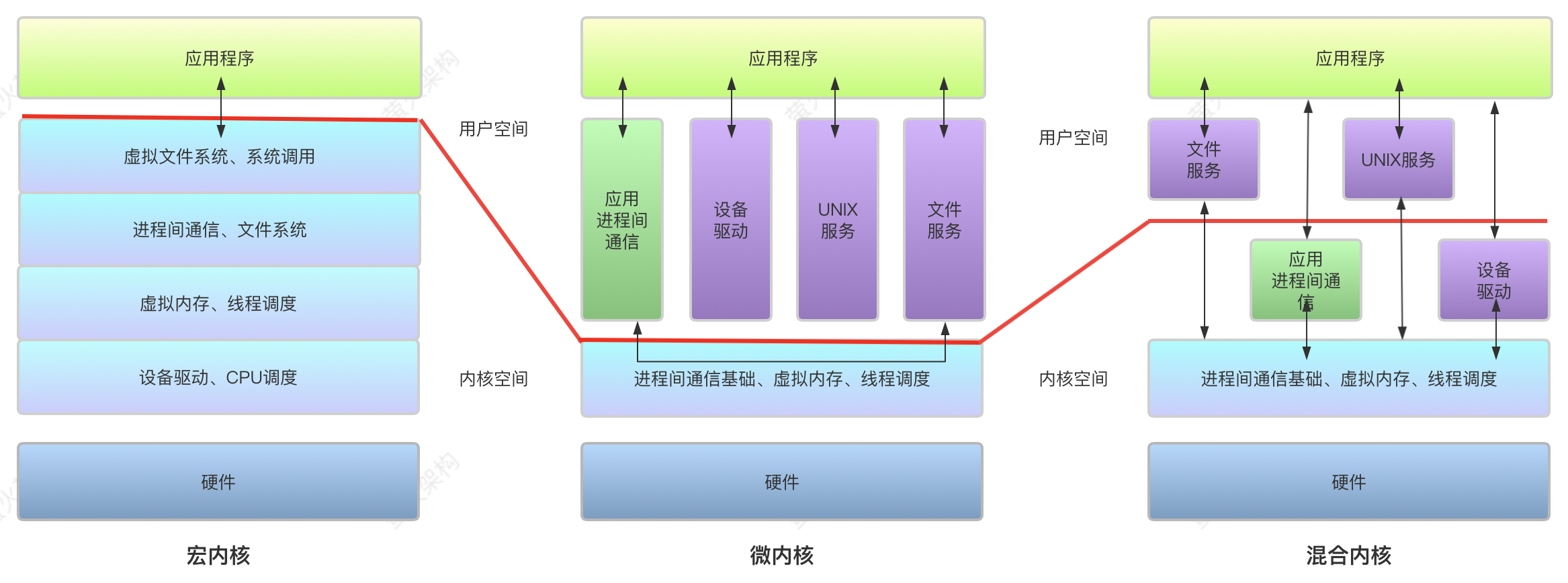
传统宏内核架构
以 UNIX/Linux,FreeBSD为代表的宏内核的文件系统 (FS) 和设备驱动 程序等 Linux 模块覆盖了其 3000 万行代码库的 80%。它们导致了大多数缺陷和 漏洞 (在过去 4 年中占 1000 个 CVE 总数的 90%), 并显著降低了可靠性和安全 性 。此外, 这些 CVE 中约有 80% 是数据泄漏, 可以通过适当的隔离来避免。因 此, 一系列的研究旨在以一种划分的方式将内核与模块隔离开来。然而, 固有 的紧密耦合需要大量的工程量, 甚至重写 。虽然 Linux 等宏内核在服务器和云等场景中占主导地位,但越来越多的新兴场景,如智能汽车和智能手机,除了良好的性能之外,还需要更好的安全性、可 靠性和可扩展性,而 Linux 并不合适。此外,Linux 很难满足此类场景所需的高级行业认证。
传统微内核架构
以 seL4 家族、Mach、zircon为代表的微内核的一个主要标志是最小化原 则,即将内核中的功能最小化,并将非核心的所有其他功能移动到用户态的独立 进程中,每个进程拥有相互隔离的地址空间,所以一个模块的故障无法传递到其 他模块影响内核整体本身。相比于宏内核,微内核更小巧、高度模块化,更容易 拓展。最先进的微内核还采用基于权限的细粒度权限访问控制,来支持最小权限 原则。因此,微内核本质上比宏内核更安全、可靠和易扩展。并且 seL4 等现代微 内核已经实现了创纪录的高性能 IPC。
然而,尽管已经被广泛研究了几十年,微内核目前主要针对特定领域,如 嵌入式和安全关键系统。由于微内核面临难以解决的兼容性问题,业界很少采用 微内核作为大规模生产使用的通用操作系统。重建整个软件生态是不现实的,现 代的先进微内核通过提供自定义 libc 库(比如 musl-libc)来实现部分 POSIX 兼容 性,这些库对于操作系统服务生成进程间通信(IPC),但是他们很难在合理的工 程量和不打折扣的性能下重用已有的设备驱动程序。另外,微内核在通用场景中 也面临着严重的性能问题,在通用场景下 IPC 频率会显著增加,微内核本身的基 于权限的细粒度访问控制也可能带来显著的性能开销。
混合内核架构
为了实现系统性能与安全可拓展性的折中,业界采用了混合内核的方案,比 如 Windows NT、Apple XNU 和 HongMeng。混合内核在内核中实现一个 最小的微内核,但不同于微内核将所有其他系统服务放在用户态的独立进程中, 其将所有系统服务以内核线程的形式运行在内核态。尽管混合内核也最大限度地 减少了核心内核中的功能,但它们没有继承微内核的许多优点。混合内核中的操 作系统服务共用内核地址空间,没有很好地隔离,因此,受损或有缺陷的系统服 务仍可能破坏系统,可能导致严重后果,如破坏用户数据。
混合内核架构是系统性能与可靠性之间的一种折中方案,由于多个内核线程仍然共享内核地址空间,所以受损的系统服务仍然有可能破坏内核或其他内核线程的内存空间。但是由于Rust语言天生具有的内存安全特性,在不使用unsafe语法的情况下,不同内核线程之间的访存隔离性可以由Rust语言来保证。
线程模型分析
在支持多线程的内核中,存在内核线程与用户线程两种线程对象,用户线程位于内核线程之上,它的管理无需内核支持,而内核线程由操作系统来直接支持与管理,只有内核线程才能通过操作系统调度以便运行于物理处理器。本节首先介绍常用的一对一和多对多线程模型设计。
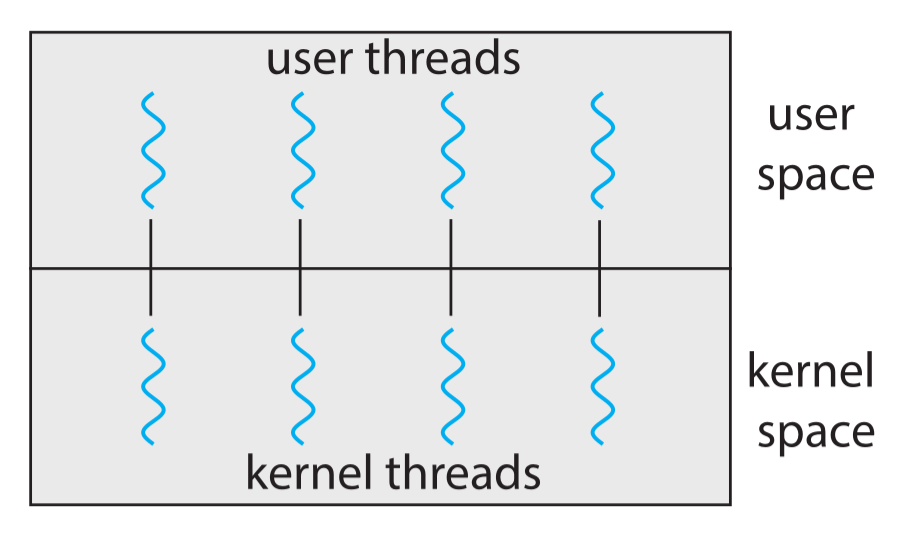
一对一线程模型
一对一模型映射每个用户线程到一个内核线程,一个用户线程阻塞系统调用时,将内核现场保存在自己的内核栈上,并调度另一个线程继续运行。这种模型允许多个线程并行运行在多处理器系统上,唯一的缺点是,创建一个用户线程就必须创建一个相对应的内核线程,由于创建内核线程的开销会影响应用程序的性能而且每个内核线程都有独立的内核栈,所以这种模型的实现大多数限制了系统支持的线程数量以避免过大的性能和内存开销。Linux 系统和 Windows 操作系统家族都实现了这种模型。下图描述了一对一线程模型的映射关系:
多对多线程模型
多对多模型多路复用多个用户线程到同样数量或更少数量的内核线程。多对多线程模型不存在一对一模型的限制,系统可以创建任意数量的用户线程,并且相应的内核线程可以在多处理器系统上并发执行,且一个线程执行阻塞系统调用时可以调度另一个线程来执行。下图描述了多对多线程模型的映射关系:
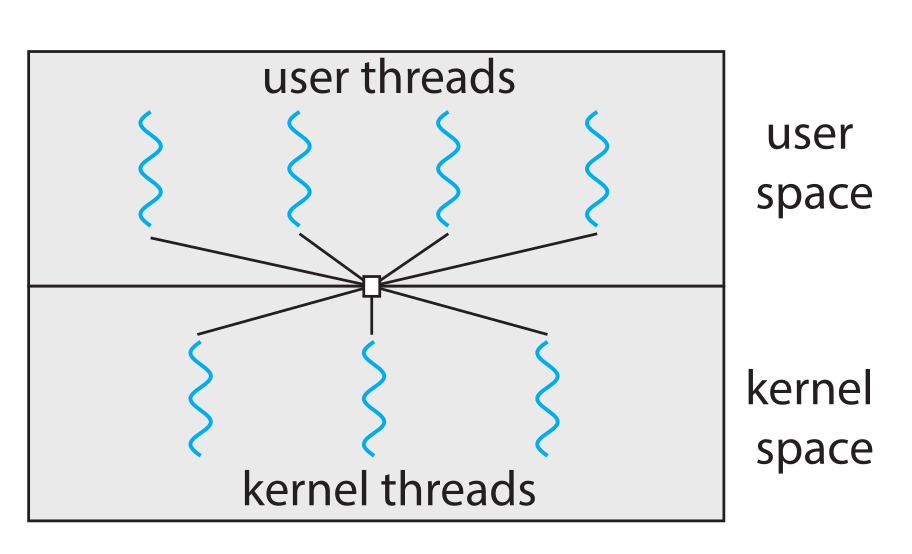
我们在多对多线程模型设计中详细介绍了nCore的线程模型设计。
项目架构与内核架构设计
项目总体架构
为了进行混合内核与宏内核的对比,本项目实现了混合内核与宏内核两种内核架构,项目总体结构如下图所示:
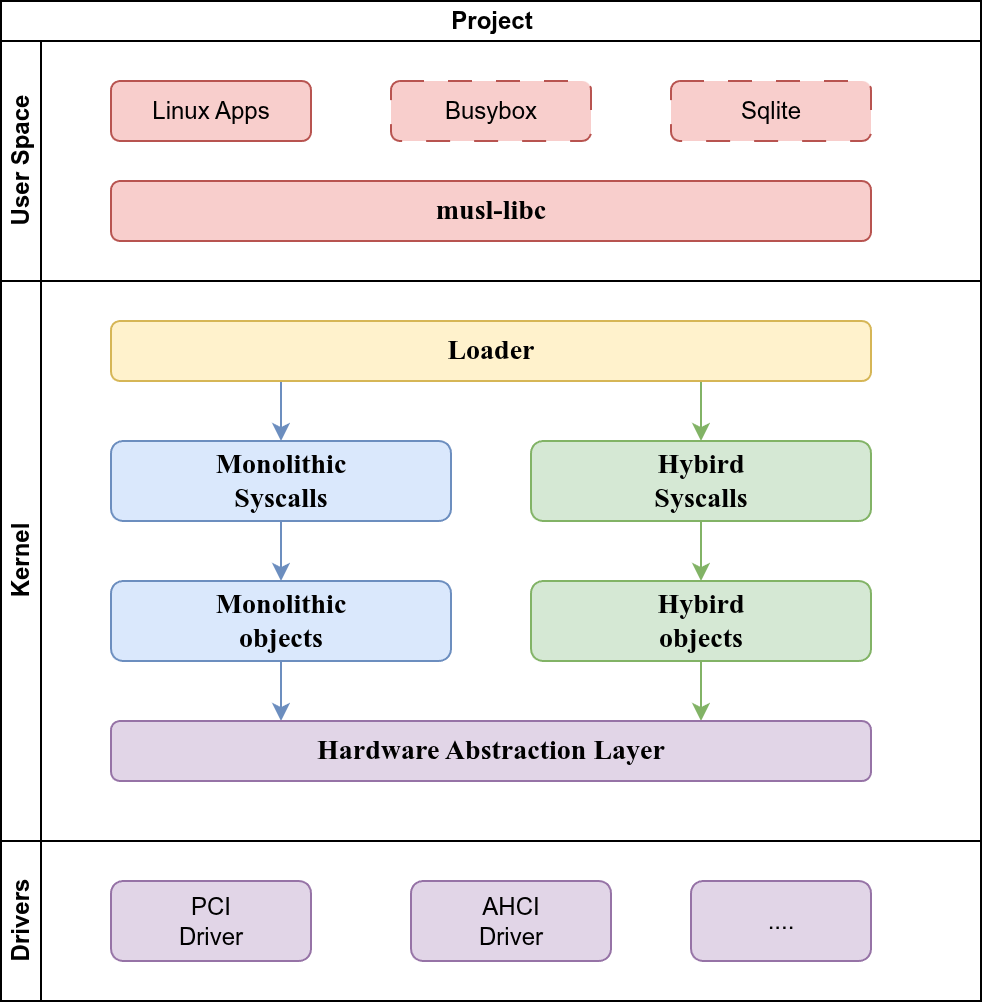
项目总体采用层次化软件开发方法,自底向上分为驱动、硬件抽象层、内核对象层、系统调用层、装载器和上层标准库和应用程序。
硬件抽象层(Hardware Abstraction Layer,HAL)定义一套硬件操作 API,提供给上层的内核对象使用,HAL层内部的实现和依赖的环境,对于上层内核对象 来说是完全透明的,且上层内核对象只能通过 HAL 层的 API 来操作硬件。HAL 层只给出接口定义,具体的实现可以有多种硬件架构,如 x86_64、aarch64 等(目前只实现了x86_64架构),在编译时通过 Rust 语言的 feature 条件编译选项将 HAL 定义的硬件接口绑定到具体的硬件平台实现上去。这种做法一方面可以将底 层的 unsafe 代码进行独立封装与集中检查测试,限制上层对象只能通过 HAL 层的 API 操作硬件,从而最大限度地利用 Rust 语言提供的内存安全特性,另一方面屏 蔽了不同硬件架构的硬件细节,使上层内核对象的操作独立于硬件。
内核对象层(Kernel Objects)基于 HAL 层给出的硬件接口,实现内核数据结 构和他们的方法(如进程线程等)。由于混合内核与宏内核的内部实现有所不同,分别实现宏内核对象和混合内核对象两套对象。
系统调用层(Syscall Layer)根据内核对象的方法实现系统调用接口。为了直接支持musl-libc,我们直接实现了Linux系统调用。
加载器(Loader)位于系统调用层之上,其向下使用系统调用层给出的系统调用 API,完成内核对象初始化、系统调用入口设定、第一个用户程序加载和启动的工作。用户程序(App)层运行用户态应用程序,可以直接使用内核提供的系统调用,也可以运行在系统调用层之上的 c 标准库(musl-libc)上。
代码目录树
项目的代码目录树如下
.
├── boot // 启动内核
├── crates // 有修改的第三方库
├── executor // 协程执行器
├── hal // 硬件抽象层
├── hybrid-objects // 混合内核对象
├── hybrid-syscalls // 混合内核系统调用
├── loader // 加载器
├── misc // 杂项
├── monolithic-objects // 宏内核对象
├── monolithic-syscalls // 宏内核系统调用
├── musl // musl源码
├── Ncore // 顶层内核
├── rcore-fs-use // 构建文件系统
├── tutorial // 文档
├── user-c // C语言用户程序
├── user-components // 用户态组件
├── user-rs // Rust用户程序
└── Question.md // 本题目简介
其中的boot、executor、hal、hybrid-objects、hybrid-syscalls、loader、monolithic-objects、monolithic-syscalls、Ncore、user-rs都被实现为单独的Rust crate。
内核服务可靠性增强设计
本章详细介绍 nCore 内核服务可靠性增强设计。4.1首先介绍nCore混合内核架构设计, 4.2节再介绍为了实现内核可靠性增强 nCore 内核设计的两种内核线程以及他们是如何协作实现多对多线程模型的, 4.3节再介绍基于多对多线程模型实现的内核服务故障恢复机制。
混合内核架构设计
我们在进行 nCore 内核架构设计时,综合考虑了宏内核与微内核架构的优劣, 基于以下几点考虑,来设计 nCore 内核架构。
• 宏内核中所有内核服务共享内核地址空间,从而提供良好的性能,但内核可 靠性和可拓展性较差,nCore 希望在提高内核可靠性和可拓展性的前提下尽 量提高内核性能。
• 微内核每个系统服务拥有独立的地址空间,具有良好的可靠性与隔离性,但 系统性能差,nCore 希望能够提供比微内核更优的性能。
• 业界曾经采用的混合内核架构如 Windows NT 在系统性能与安全可拓展性之 间采取折中的方案,将不同的系统服务一定程度上隔离为独立的内核线程, 但仍然共享内核地址空间,受损或有缺陷的系统服务仍然可能破坏其他系统 服务,但是 Rust 语言具有天生的内存安全特性,在不使用 unsafe 代码块的 情况下,正确的内核代码不会产生非法的内存操作以破坏其他的内核数据结 构,可以利用 Rust 语言的内存安全特性来实现混合内核中内核数据结构的 访存隔离性。
• nCore 的设计目标是权衡系统性能与可靠可拓展性,在微内核与宏内核之间 选择折中的混合内核,最终提供比微内核更好的性能,比宏内核更好的可靠 可拓展性。
从以上几点出发,我们将 nCore 设计为下所示的架构。非核心系统服务运行在独立的由 Rust 语言保证内存隔离性的内 核服务线程中,协程执行器内核线程轮询所有用户线程。两种内核线程共同为所有用户线程服务最终构成一个多对多线程模型(多对多线程模型设计)。
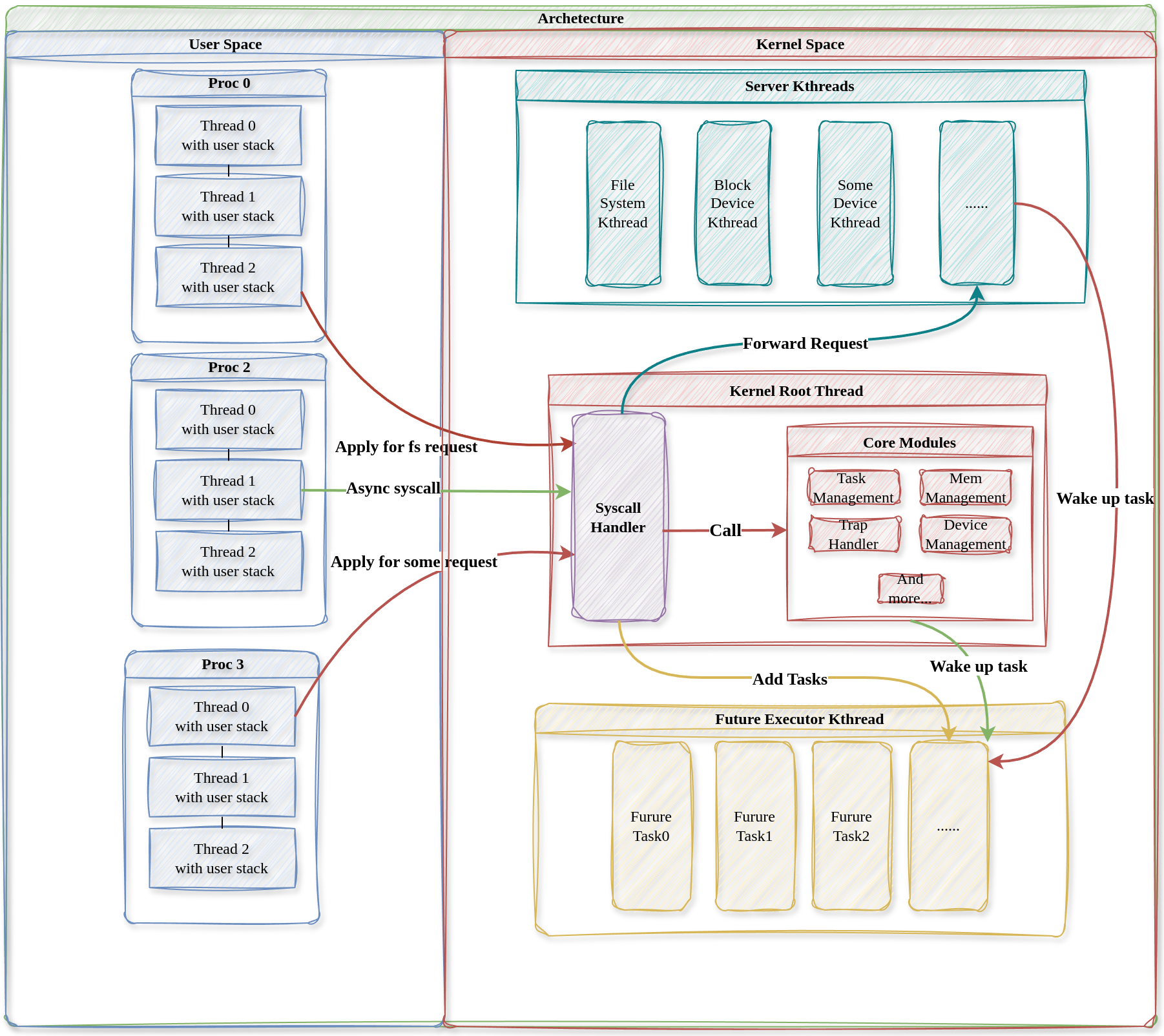
多对多线程模型设计
nCore 混合内核为了将非核心系统服务(如文件系统服务)与内核核心服务 相互隔离,降低非核心系统服务的特权,将非核心系统服务放在独立的内核服务线程中执行。为了处理内核中产生的异步请求和系统调用,利用 Rust async 机制设计一个协程执行线程用于执行内核产生的所有异步任务。两种内核线程的功能总结如下:
• 内核服务线程:提供非核心服务的内核服务
• 协程执行器线程:其负责协作式调度内核中的所有用户线程
两种内核线程协作起来,共同服务所有用户线程,从而实现了一个多对多线程模型。本节我们分别介绍两种内核线程。
协程执行器线程设计
async Rust简介
异步任务和Future trait
在 nCore 中,内核有时会产生不能立刻完成而需要等待的操作,比如异步式系统调用(如读磁盘)和内核服务线程模型(用户线程向内核服务线程发送请求后不能立马得到服务),我们称这种操作为异步任务。为了支持异步编程,Rust语言在核心库中提供了 Future Trait,表示实现了此 Trait 的结构体可能是一个尚未准备好的值,Future Trait 可以很好地表示内核中一个可能尚未完成的异步任务。Future Trait 对外暴露出一个 poll 接口,poll 接口接受代表当前 Future 上下文的 context 参数,用于轮询 Future 对象,每次 poll 可能返回执行成功或需要阻塞,内核通过不断调用 poll 接口,就可以查询异步任务是否执行结束从而进行下一步操作。context 变量的 wake 方法可以用于唤醒 Future 对象,通知内核 Future 应该再次被轮询(即被内核查询)。
多个 Future 可以进行组合、嵌套。在编译期,Rust 编译器将顶层的 Future 变成一个带有多个状态的状态机;在运行时,对于顶层 Future 的 poll 操作可能导致内部低层次的 Future 的poll 操作从而进入另一个中间状态或者终态。想要在内核中使用 Rust 的 async 机制和 Future Trait,我们需要一个用于轮询顶层 Future 的协程执行器(Executor),在 std 环境下,通常可以使用第三方库提供的 Executor,但是在 no_std 下,核心库 core 不提供实现,所以我们需要独立实现一个全局 Executor 来管理内核中产生的所有顶层 Future 对象。
层次化Future设计实现
nCore 内核中产生多种异步操作,这些操作都被实现为 Rust 语言提供的 Future Trait 对象,底层 Future 可以嵌套组合成为更高层次的 Future 从而实现复杂的异步逻辑,本节我们介绍几个底层 Future 和高层 Future 的实现,说明他们是怎么与Executor 协作的。
ThreadSwitchFuture是内核中最顶层的Future,其直接被Executor轮询,代表了新建一个用户线程,将其加入内核线程队列中等待执行。当协程执行器轮询此Future时,会首先设置当前线程并切换内核地址空间,最后轮询线程的控制流函数,即内部的Future,实际上其会轮询下面的run_user函数从而执行用户线程。
/// Top level future, directly polled by the executor.
///
/// Make sure every time poll this future, modify the CURRENT_THREAD.
pub struct ThreadSwitchFuture {
thread: Arc<Thread>,
future: Mutex<ThreadFuturePinned>,
}
impl ThreadSwitchFuture {
/// Spawn a new thread that can be polled by executor.
pub fn new(thread: Arc<Thread>, future: ThreadFuturePinned) -> Self {
Self {
thread,
future: Mutex::new(future),
}
}
}
impl Future for ThreadSwitchFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
// Switch vm.
self.thread.proc.lock().vm.activate();
set_current_thread(Some(self.thread.clone()));
// Poll thread fn.
let ret = self.future.lock().as_mut().poll(cx);
set_current_thread(None);
ret
}
}
run_user函数是一个高层Future,其代表了一个用户线程的控制流逻辑,用户线程不断进入用户态运行,陷入内核处理中断或系统调用,直到线程退出为止。其中使用的系统调用处理分发函数handle_user_trap也是一个Future。
/// 用户线程入口
///
/// loop:
/// - Get UserContext
/// - 进入用户态
/// - 处理中断/系统调用
/// - Put back UserContext
async fn run_user(thread: Arc<Thread>) {
loop {
if thread.inner.lock().state == ThreadState::Exited {
break;
}
// 进入用户态
let mut context = thread.begin_running();
if let Some((_idx, info, sigmask)) = thread.handle_signal() {
context = handle_signal(thread.clone(), context, info, sigmask);
}
context.run();
// 返回内核,处理中断/系统调用
handle_user_trap(thread.clone(), &mut context).await;
thread.end_running(context);
}
}
handle_user_trap函数处理系统调用或中断,其中系统调用分发函数syscall也是一个异步函数。可见,内核中通过底层的Future的组合嵌套,最终形成顶层Future而被Executor轮询,全局Executor轮询多个顶层Future(即用户线程)从而实现一个内核线程服务所有用户线程。(区别于Linux的一对一线程模型)。
/// 处理用户态中断或系统调用
async fn handle_user_trap(thread: Arc<Thread>, ctx: &mut Box<UserContext>) {
// 用户态系统调用
if ctx.trap_num == 0x100 {
//...
let ret = syscall.syscall(syscall_num, args).await;
ctx.set_syscall_ret(ret as _, 0);
return;
}
// 内核或用户中断
match ctx.trap_num {
PAGE_FAULT => {
// handle
}
TIMER => {
// handle
}
_ => {
unimplemented!();
}
}
}
协程执行器Executor设计实现
根据上面的讨论,我们知道Executor内核线程运行内核中的所有顶层Future(用户线程),下面我们讨论其实现。
协程执行器的控制流很简单,其循环取出可以查询的任务(sleep 标记为 false),并查询任务执行状态,若任务执行完毕,则进行下一次循环;若任务还在 执行中,则将此任务的 sleep 标记修改为 true,并将此任务重新加入任务队列中。 尚未完成的任务在其代表的异步操作完成后,sleep 标记会被重新修改为 false,从 而执行器会再次查询此任务,并返回成功。通过 sleep 标记的设计,任何一个异步 任务最多会被执行器查询两次。
下图描述了协程执行器内核线程的结构和控制流,协程执行器作为一个独立 的内核线程,负责处理内核中产生的所有异步任务。其维护了一个任务队列,任 务队列中的每一个任务都包含了一个 sleep 标记,用于表示此任务是否应该被执行 器查询,sleep 标记为 true 时,执行器暂时不查询此任务。
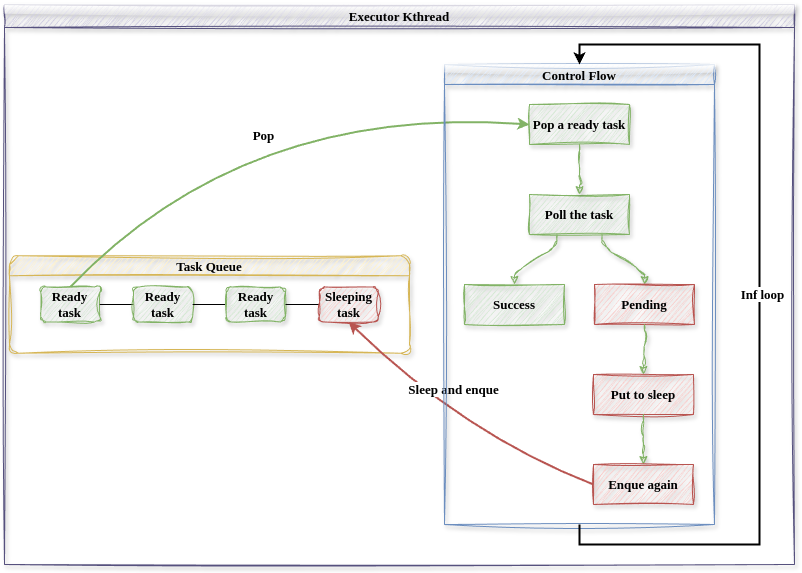
最终Executor暴露出spawn和run_until_idle接口,内核使用这些接口来添加用户线程和执行Executor。
/// 运行执行器直到没有就绪任务
pub fn run_util_idle() {
EXECUTOR.get().set_state(ExecutorState::NeedRun);
// 轮讯协程,直到任务队列中无就绪任务才停止
EXECUTOR.run_until_idle();
// 此时执行器任务队列中无就绪任务
EXECUTOR.get().set_state(ExecutorState::Idle);
}
/// 是否需要调度执行
pub fn need_schedule() -> bool {
EXECUTOR.get().state() == ExecutorState::NeedRun
}
/// 添加协程到执行器队列中
pub fn spawn(future: impl Future<Output = ()> + Send + Sync + 'static) {
// 创建协程任务
let weak_executor = Arc::downgrade(EXECUTOR.get());
let task = Task::new(future, weak_executor);
// 添加到执行器队列中
EXECUTOR.get().add_task(task);
// 协程执行器线程需要运行
EXECUTOR.get().set_state(ExecutorState::NeedRun);
}
内核服务线程设计
设计原则
操作系统内核提供的服务大致可以分为核心服务(如虚拟内存管理、进程线程管理、中断和系统调用管理)和非核心服务(如文件系统服务、设备驱动服务)。驱动程序等非核心服务代码质量有好有坏,为了防止其破坏内核地址空间,微内核将非核心服务实现为用户态的进程,每个进程都有由硬件保证的隔离的地址空间,从而每个非核心服务保持独立性且不能破坏任何内核数据结构。但是频繁的地址空间切换也导致了显著的性能开销。与微内核相反,在 Linux 这种宏内核中,驱动程序等非核心服务直接运行在内核空间中,运行时其地位与内核代码等价,如果一个低质量的驱动程序崩溃,那整个系统也就崩溃了,从而提供了较好的性能但可靠性较差。
混合内核内核服务线程的设计是在宏内核与微内核两者之间的一种折中:类似于微内核,混合内核将每个非核心的系统服务放置在一个相对独立的内核服务线程中,其拥有独立的内核栈与控制流,由 Rust 语言本身来一定程度地保证多个内核服务线程的访存隔离性,然而所有内核服务线程共享内核地址空间,这样相对于微内核而言,不同的内核服务线程通信时不需要切换地址空间从而避免了昂贵的性能开销。
本质上来说,我们认为内核服务线程中运行的驱动程序代码不完全可靠,有可能崩溃,然而独立的内核服务线程设计允许在某个内核服务线程崩溃时不影响内核整体,也不影响其他的内核服务线程,内核可以尝试重启崩溃的内核服务线程。
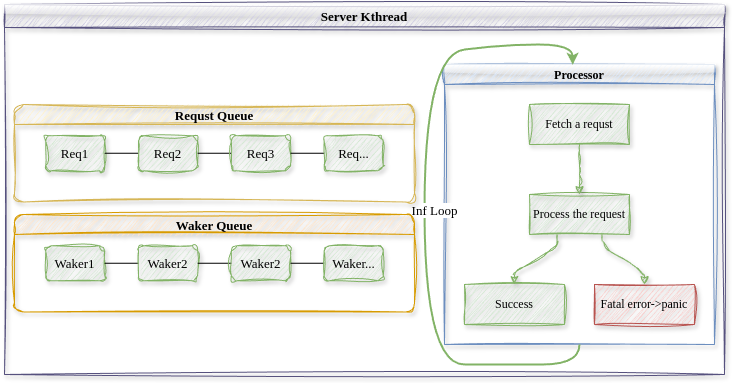
上图描述了内核服务线程的结构。类似于微内核中不同的用户进程之间采用 消息(Message)传递的方式进行通信,在混合内核中,用户线程通过发送请求 (Request)的方式请求内核线程服务,请求是用户线程对于自己希望获得的服务 进行的描述,用户线程需要内核提供的非核心服务时,其构造一个请求并通过内 核将其发送给对应的内核服务线程。一个特定的内核服务线程服务所有需要这种 内核服务的用户线程,所以内核服务线程中维护一个待完成的请求队列(Request Queue),内核服务线程从请求队列中取出并解析请求,完成相应的服务后,通过 唤醒器(Waker)通知发出请求的用户线程。唤醒器是内核服务线程持有的发出请 求的用户线程的一个句柄,用于在请求完成时通知用户线程以改变它的状态,因 此内核服务线程还维护一个唤醒器队列(Waker Queue)。 在基于请求和唤醒的通信方式下,所有内核服务线程的控制流保持一致的形 式,即不断循环,取出请求队列中就绪的请求,处理请求,再通知发出请求的用 户线程请求已经处理完毕。
自定义请求
/// 内核线程
///
/// 每个内核线程有独立的内核栈
#[derive(Default)]
pub struct Kthread {
/// 内核线程ID
ktid: usize,
/// 内核线程名称
name: String,
/// 内核线程的内核态上下文
context: Cell<Box<KernelContext>>,
/// 运行状态
state: Cell<KthreadState>,
/// 服务类型
#[allow(unused)]
ktype: KthreadType,
/// 用户请求的实际处理器
processor: Option<Arc<dyn Processor>>,
/// 请求队列
request_queue: Cell<VecDeque<(Request, usize)>>,
/// 请求的唤醒器队列
request_wakers: Cell<Vec<(Waker, usize)>>,
/// 最新的请求ID
request_id: Cell<usize>,
/// 已经响应的请求ID
response_id: Cell<usize>,
/// 当前正在处理的请求的ID
current_request_id: Cell<usize>,
}
Kthread结构体描述了内核服务线程,其包含了一个请求队列,其中存放了所有用户程序发送的请求。请求其实是一个字节序列:
/// 用户向内核线程发送的请求
///
/// 用户发送请求时将其转化为字节,用户态再重新解析
pub type Request = Vec<u8>;
用户线程在发送请求时将请求类型转为字节,内核线程在处理请求时需要将字节解析为具体的请求类型。下面是文件系统服务的请求类型实例。
pub type Fd = usize;
pub type Pid = usize;
pub type BufPtr = usize;
pub type BufLen = usize;
pub type PathPtr = usize;
pub type FLAGS = u32;
pub type FdPtr = usize;
pub type ResultPtr = usize;
/// 文件系统类请求描述信息
#[derive(Debug, Clone, Copy)]
pub enum FsReqDescription {
/// 读磁盘文件,在sys_read中被构造
Read(Pid, Fd, BufPtr, BufLen, ResultPtr),
/// 写磁盘文件,在sys_write中被构造
Write(Pid, Fd, BufPtr, BufLen, ResultPtr),
/// 打开一个磁盘文件,将句柄写入FdPtr中,
/// 在sys_open中构造
Open(Pid, PathPtr, FLAGS, FdPtr),
}
impl CastBytes for FsReqDescription {}
请求处理
/// 服务内核线程统一入口,内部通过内核线程的
/// processor对象来具体处理请求
pub fn processor_entry() {
// 获取内核线程
let kthread = CURRENT_KTHREAD.get().as_ref().unwrap().clone();
// 获取请求处理器
let processor = kthread.processor();
let processor = processor.unwrap();
// 循环响应请求
loop {
// 获取请求
let (req, req_id) = match kthread.get_first_request() {
Some((req, req_id)) => {
kthread.set_current_request_id(req_id);
(req, req_id)
}
None => {
// 请求队列为空,则设置自己为Idle,放弃CPU直到请求入队时改变状态为NeedRun
kthread.set_state(KthreadState::Idle);
Scheduler::yield_current_kthread();
continue;
}
};
// 处理请求
processor.process_request(req);
// 响应请求,唤醒等待协程
kthread.wake_request(req_id);
}
}
所有内核服务线程的控制流都保持一致,即不断循环,处理自己请求队列中的请求,并唤醒等待的用户线程。上面的processor是由内核服务线程类型决定的请求处理器,不同的驱动程序有不同的处理器,由其完成具体的处理过程。
内核服务线程故障恢复机制设计
基于panic的故障恢复机制
我们认为内核服务线程中运行的代码是不完全可靠的,可能会发生故障,内核如何捕获内核服务线程中的错误并进行恢复处理呢?下面的流程图解释了具体的控制流。
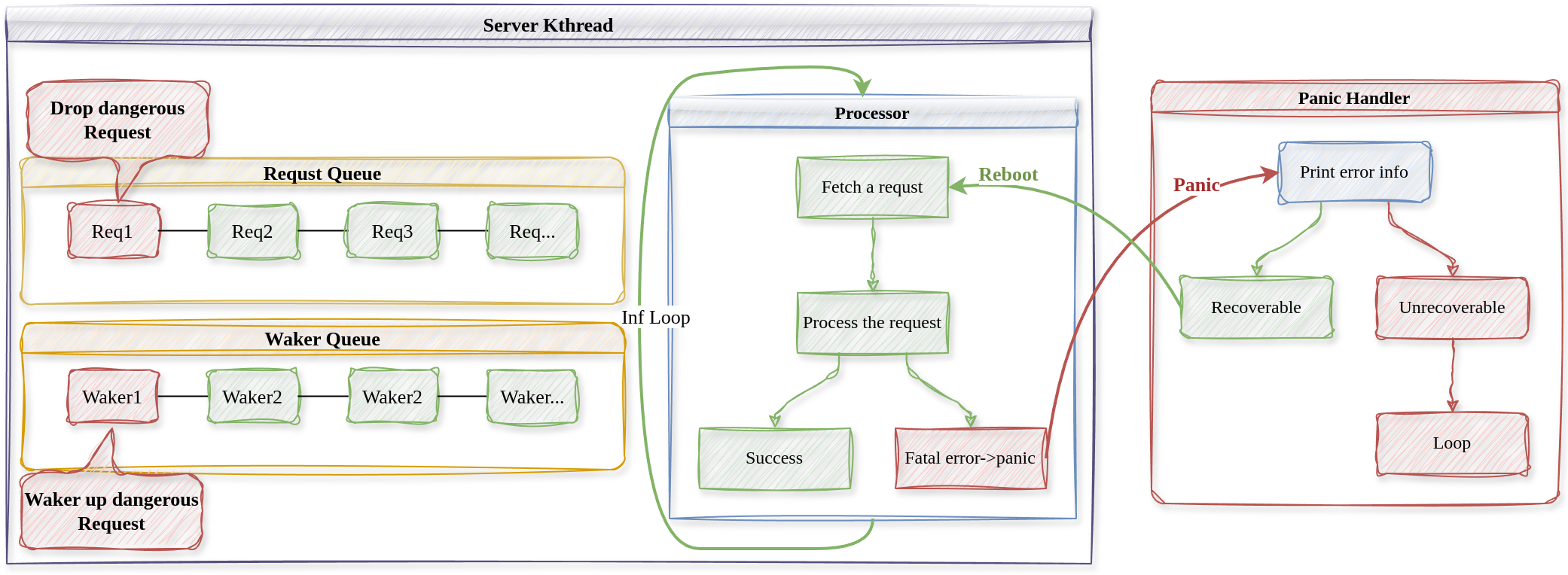
上图中,红色的部分表示有错误的控制流或请求,绿色表示正常的控制流。
当程序发生某些严重的错误时,Rust会抛出panic异常,这时控制流会跳转到程序中的全局panic处理程序panic handler中,我们就在panic handler中尝试恢复内核线程。
#[panic_handler]
fn panic(info: &PanicInfo) -> ! {
// 打印错误信息
....
// 若是内核服务线程崩溃了,尝试恢复错误
let current_kthread = CURRENT_KTHREAD.get().as_ref().unwrap().clone();
match current_kthread.ktype() {
KthreadType::BLK | KthreadType::FS => {
let current_req_id = current_kthread.current_request_id();
println!(
"\x1b[31m[Panic handler] Trying to Reboot..., the dangerous request(ID: {}) will be dropped!\x1b[0m",
current_req_id
);
// 重启内核线程
current_kthread.reboot(current_kthread.clone());
}
}
loop {}
}
panic handler首先将错误信息打印出来告知用户,再判断错误是否可以恢复,若是内核服务线程发生错误,则尝试重启内核线程以恢复错误。
/// 重启内核线程,当内核线程内发生严重错误panic时在panic handler中使用(测试)
///
/// 首先唤醒出现错误的请求,重启后不再处理
///
/// 重置当前内核线程的rip和rsp,并不保存上下文切换到其他内核线程执行
pub fn reboot(&self, current_kthread: Arc<Kthread>) {
// 重置上下文
let current_req_id = self.current_request_id.get().clone();
let context = self.context.get_mut();
context.rip = processor_entry as usize;
context.regs.rsp =
KERNEL_STACK_BASE + self.ktid * KERNEL_STACK_SIZE * 2 + KERNEL_STACK_SIZE;
// 唤醒出错的请求
self.wake_request(current_req_id);
let kthread = Scheduler::get_first_kthread().unwrap();
KTHREAD_DEQUE.get_mut().push_back(current_kthread.clone());
// 修改全局变量,且不保存寄存器
*CURRENT_KTHREAD.get_mut() = Some(kthread.clone());
current_kthread.switch_to_without_saving_context(kthread);
}
重启内核线程时,首先唤醒出错的请求,不然等待的内核线程将永远处于等待状态,我们认为出错的请求是危险的,将其丢弃重启后不再处理。然后将内核线程rip和rsp现场恢复到初始状态,当调度器再次调度错误内核线程时,从下一个请求开始继续处理。
用户程序支持
非系统程序员一般不直接使用操作系统提供的系统调用接口,而是使用标准库(如libc),标准库定义了用户程序真正的入口_start,其完成用户堆栈的初始化工作,并进入用户程序执行。其还实现一组实用的接口以方便程序员使用,在标准库之上,就可以构建丰富的软件生态。
因此为操作系统实现或支持标准库是非常重要的,本章我们介绍如何为nCore内核支持标准库,并如何基于标准库支持Linux原生用户程序。
musl-libc支持
C 语言标准库(libc)是用户程序的最底层 API。目前几乎所有的用户程序都建立在某个 libc 之上,极少直接和系统调用打交道。而不同的 libc 所使用的系统调用也有细微区别,因此选择一个合适的 libc 就尤其重要。我们平时最常用的是 glibc,它功能全面但是过于复杂,一个从零实现的系统难以支持。musl-libc 是一个轻量级、快速、标准兼容的 C 标准库(libc)实现,专为 嵌入式系统、容器化环境和高性能应用 设计。相比 GNU C 库(glibc),musl 更加精简,强调 代码简洁性、正确性及可维护性,适用于静态链接和资源受限的环境。因此支持musl-libc是一个很好的选择。
由于musl-libc依赖于Linux系统调用,因此我们选择直接实现Linux系统调用,只要再实现Linux的部分abi兼容,就可以支持musl-libc了。
我们在已有的Linux开发环境下下载并编译好musl-libc,并编写一个简单的hello程序:
#include <stdio.h>
int main(){
int a = 100;
printf("Hello world!\n");
return 0;
}
使用musl提供的musl-gcc脚本来编译这个c程序,采用静态链接:
musl-gcc -static -o bin/hello src/hello.c
得到的二进制文件可以直接在Linux开发环境中运行,我们希望能够不加修改的在nCore中运行这个elf文件。可以使用strace命令来查看这个elf文件使用的系统调用,因此想要在nCore中运行hello,需要实现这些系统调用。
strace ./hello
execve("./hello", ["./hello"], 0x7ffca3042430 /* 65 vars */) = 0
arch_prctl(ARCH_SET_FS, 0x406658) = 0
set_tid_address(0x406790) = 62822
ioctl(1, TIOCGWINSZ, {ws_row=29, ws_col=182, ws_xpixel=0, ws_ypixel=0}) = 0
writev(1, [{iov_base="", iov_len=0}, {iov_base="\n", iov_len=1}], 2
) = 1
writev(1, [{iov_base="Hello world!, a = 100", iov_len=21}, {iov_base="\n", iov_len=1}], 2Hello world!, a = 100
) = 22
exit_group(0) = ?
+++ exited with 0 +++
因此,理论上只要实现了相应的系统调用,我们就可以运行Linux生态中的任意C语言用户程序了。
Busybox支持
BusyBox 是一个高度精简的 嵌入式 Linux 工具集,将 上百种常用 Unix/Linux 命令行工具(如 ls、cp、sh、grep、vi 等)集成到一个 单个可执行文件 中,大幅节省存储空间和内存占用。它被广泛用于嵌入式设备、救援系统、容器基础镜像 等资源受限环境。
Busybox自带了shell程序,若系统支持busybox,就可以直接使用其ash作为默认程序,并且提供常用的Linux工具集支持。
我们可以自己下载并编译busybox,为此我们需要关闭busybox配置中的一些功能,并且采用静态链接,最终使用musl-gcc进行编译即可。
若觉得自己编译太复杂,也可以采用musl-libc预编译好的二进制文件,直接打包到文件系统中运行。
附录:效果演示
由于时间关系,目前只支持了Qemu平台。下面给出了一些在Linux系统上使用Qemu运行的效果演示:
以宏内核和混合内核两种模式运行内核
内核通过Rust语言的feature特性来在编译时确定内核架构,想要运行宏内核模式或混合内核模式,在项目根目录输入:
make run feature=monolithic
make run feature=hybrid
宏内核运行效果如下:

测试混合内核的故障恢复功能
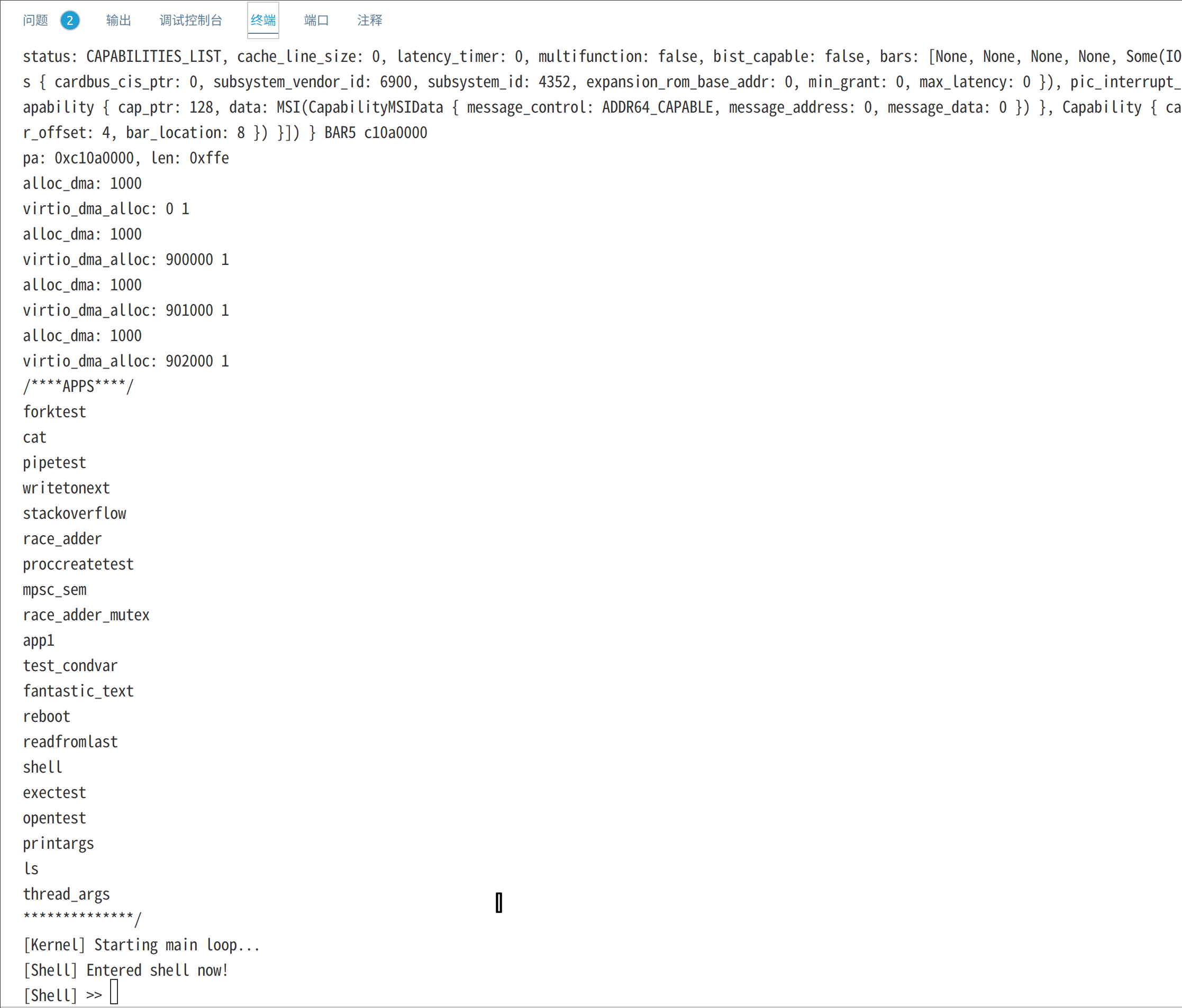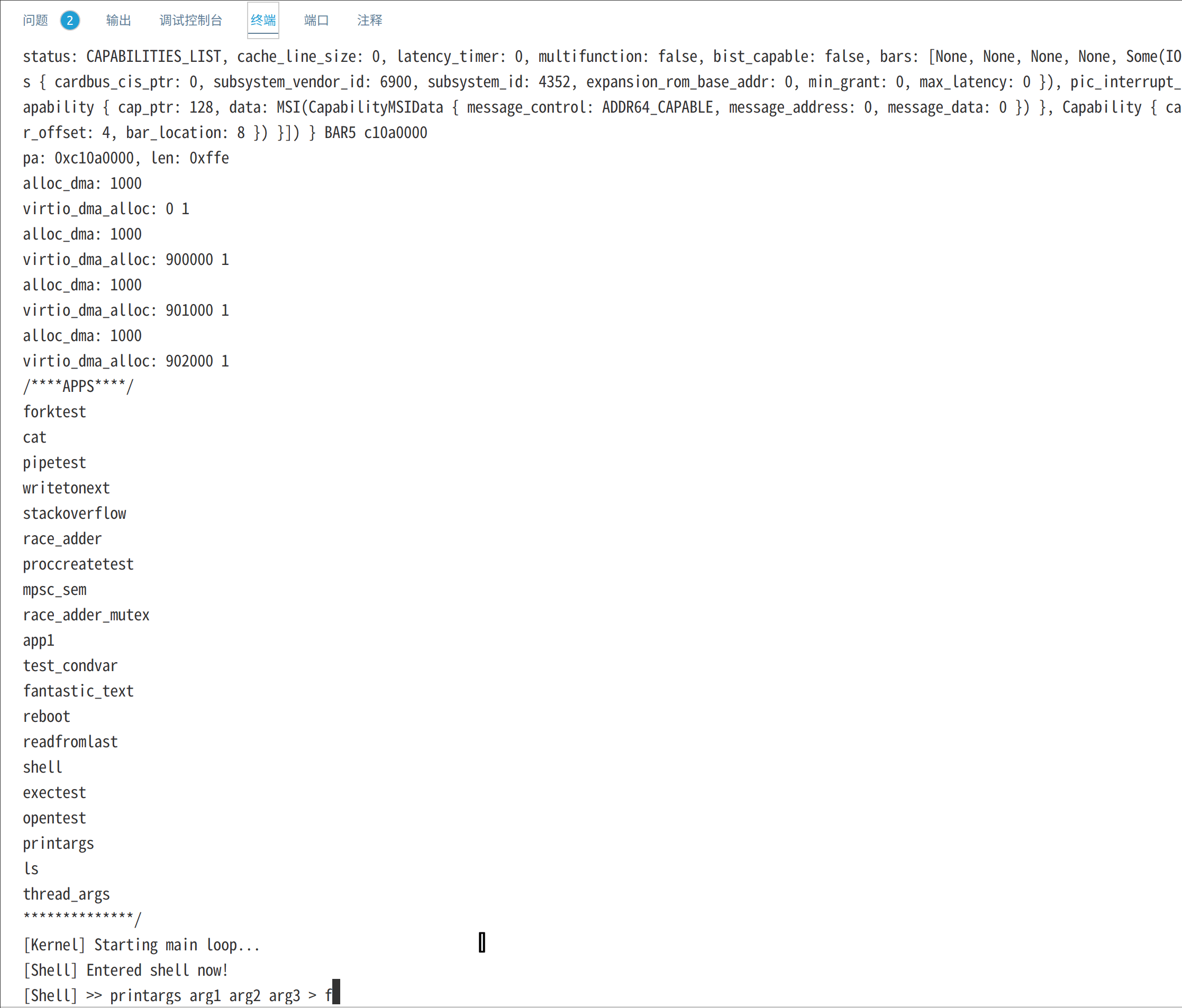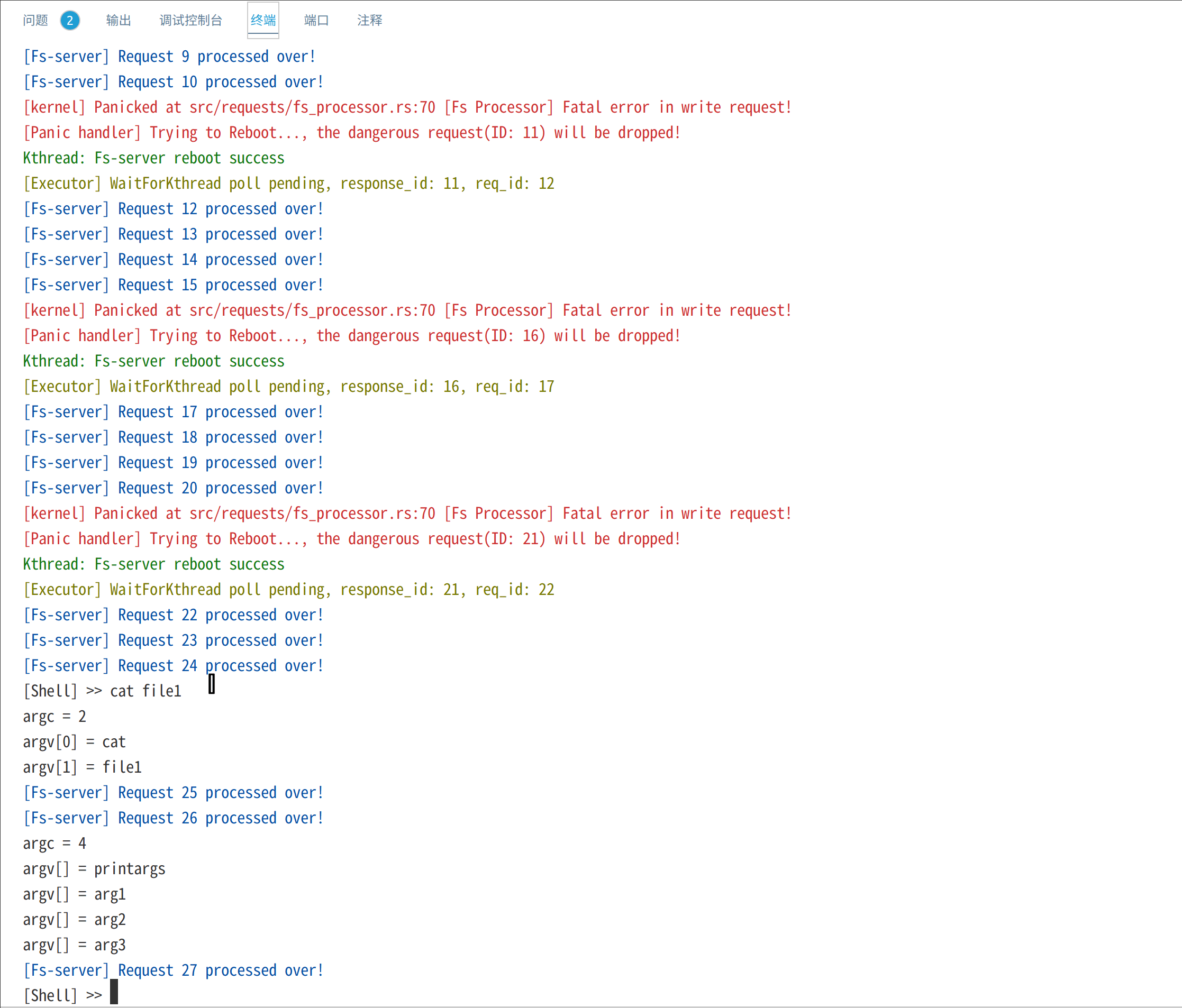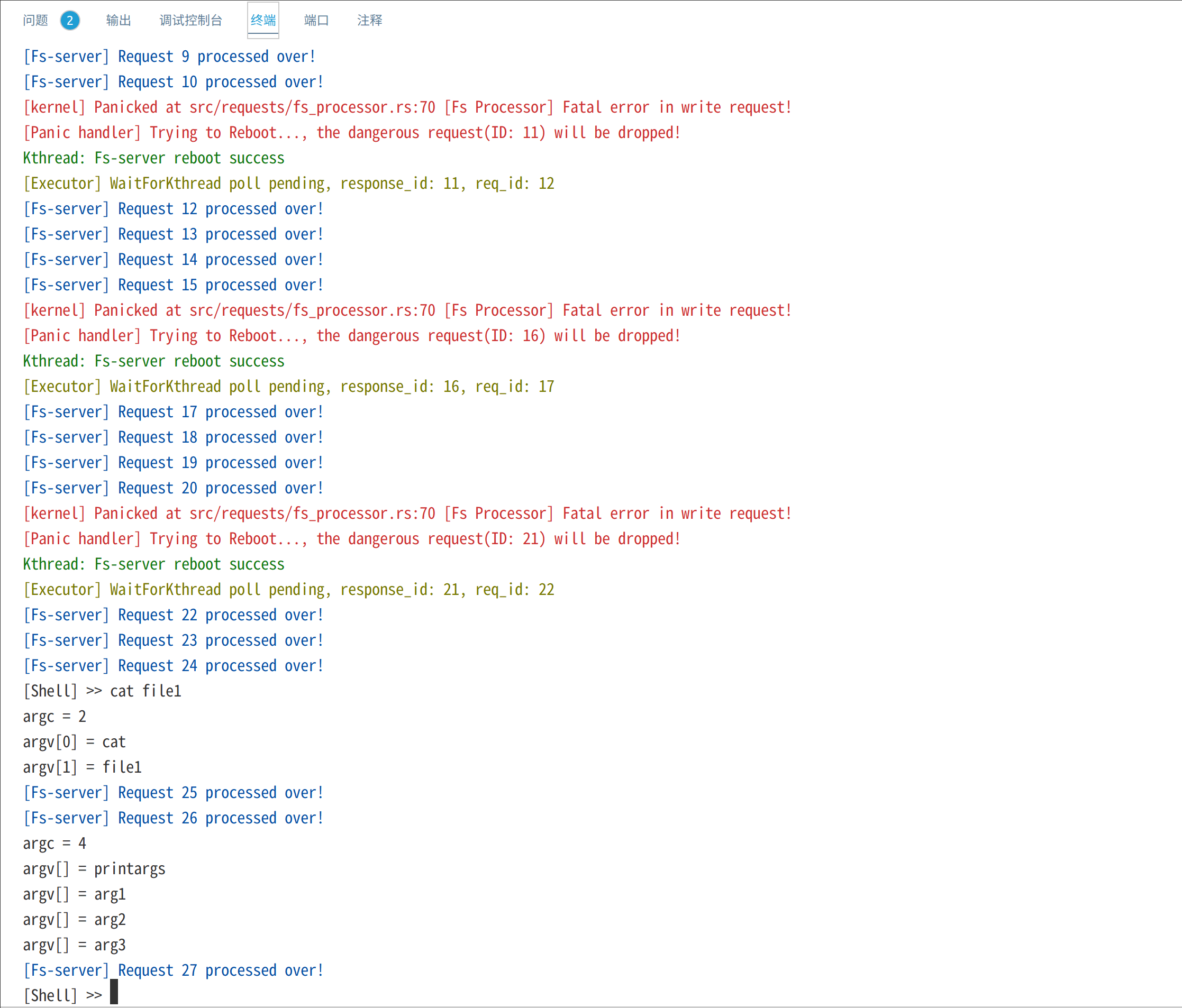
reboot测试创建文件filea,并进行20次write系统调用,每次写入一个字符'a'。在文件系统内核服务线程的processor中,我们设置每响应5次write请求,就触发一个panic,以测试内核是否能够重启文件系统内核线程:
// Write请求,进程Pid将buf中的数据写入文件表中fd对应的文件
FsReqDescription::Write(pid, fd, buf_ptr, buf_len, result_ptr) => {
// 切换到进程所在地址空间
activate_proc_ms(pid.clone());
// [模拟致命错误]
if PROCESSED_COUNT.load(Ordering::Relaxed) % 5 == 0 {
PROCESSED_COUNT.fetch_add(1, Ordering::Relaxed);
panic!("[Fs Processor] Fatal error in write request!");
}
...
}
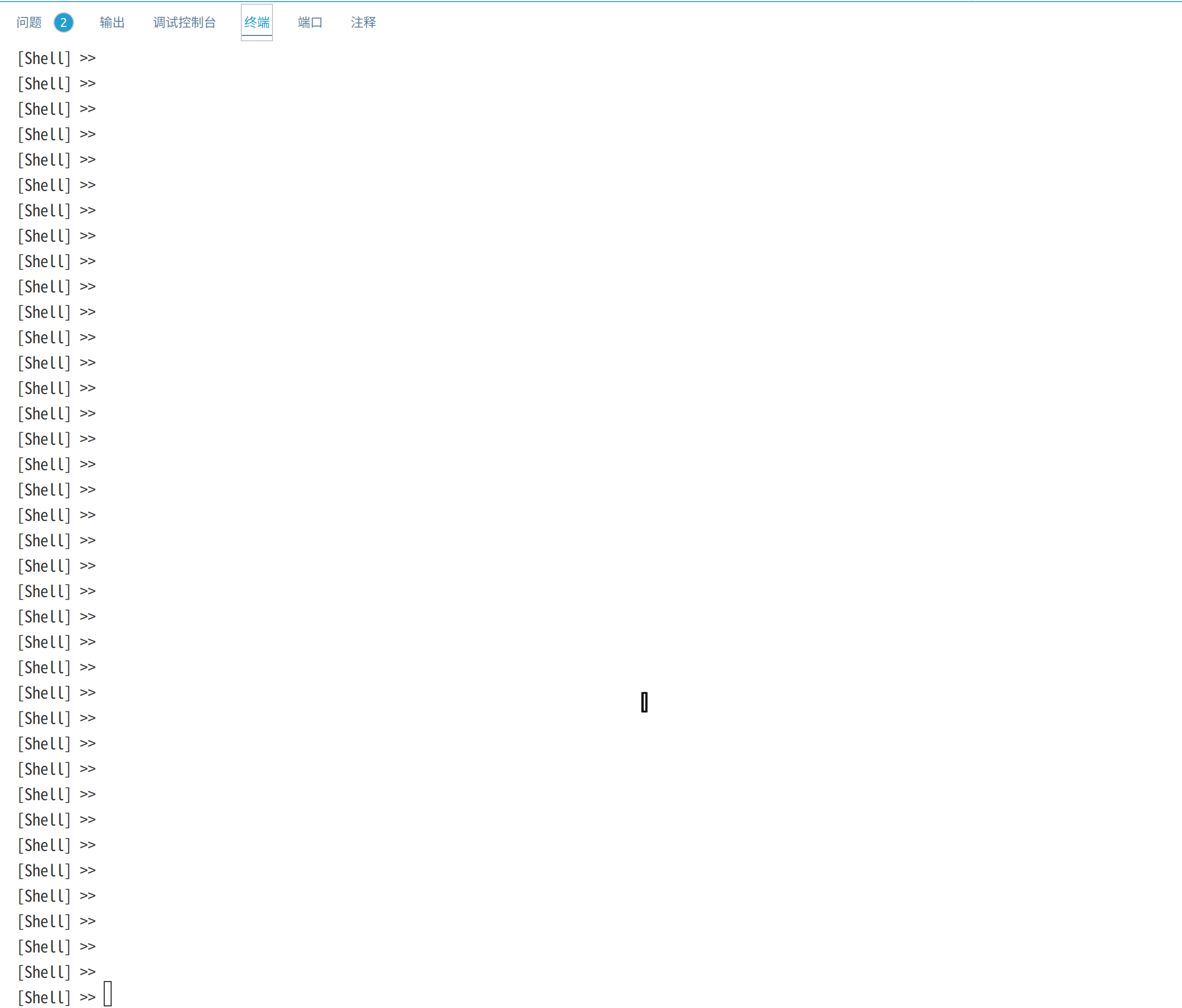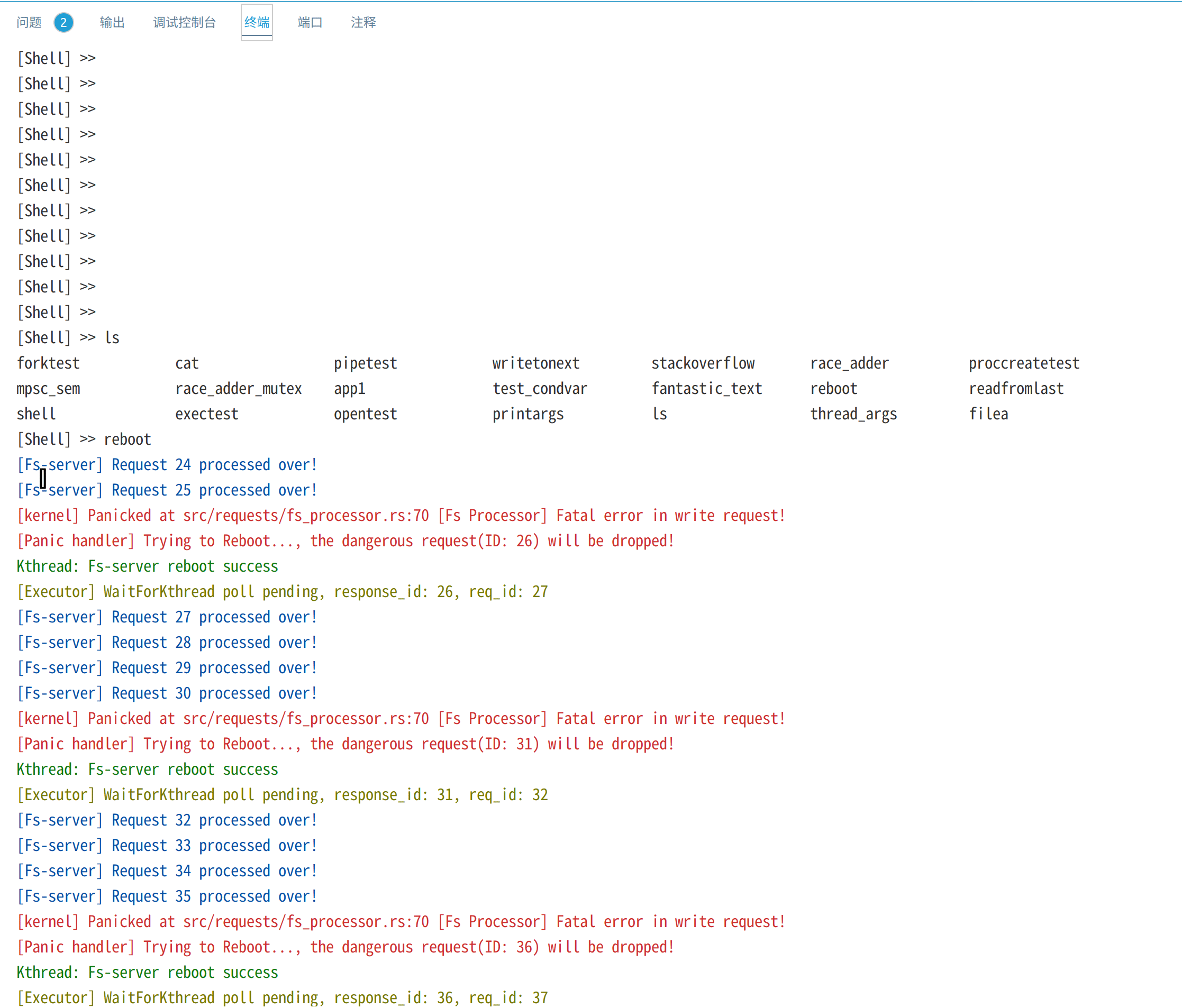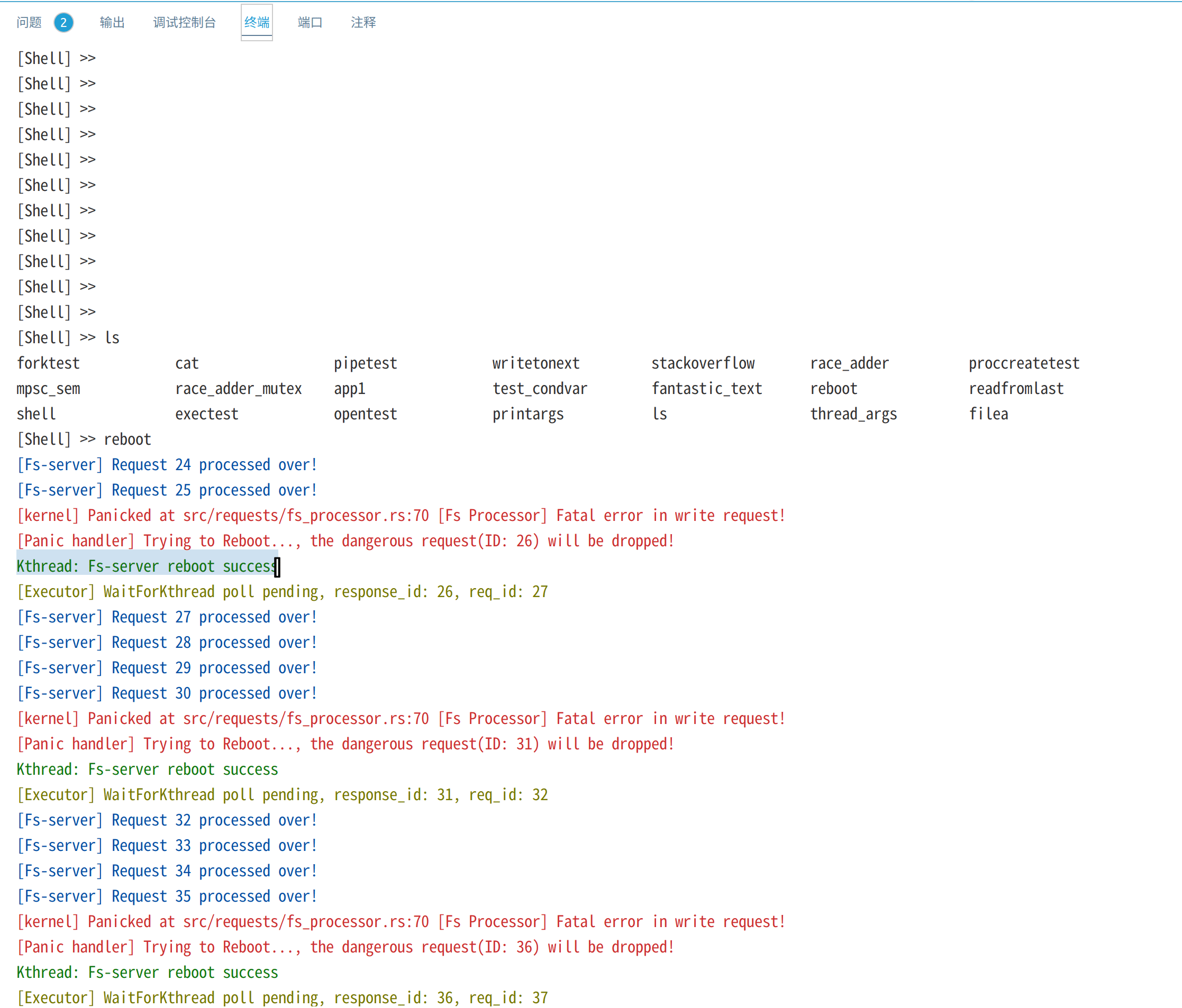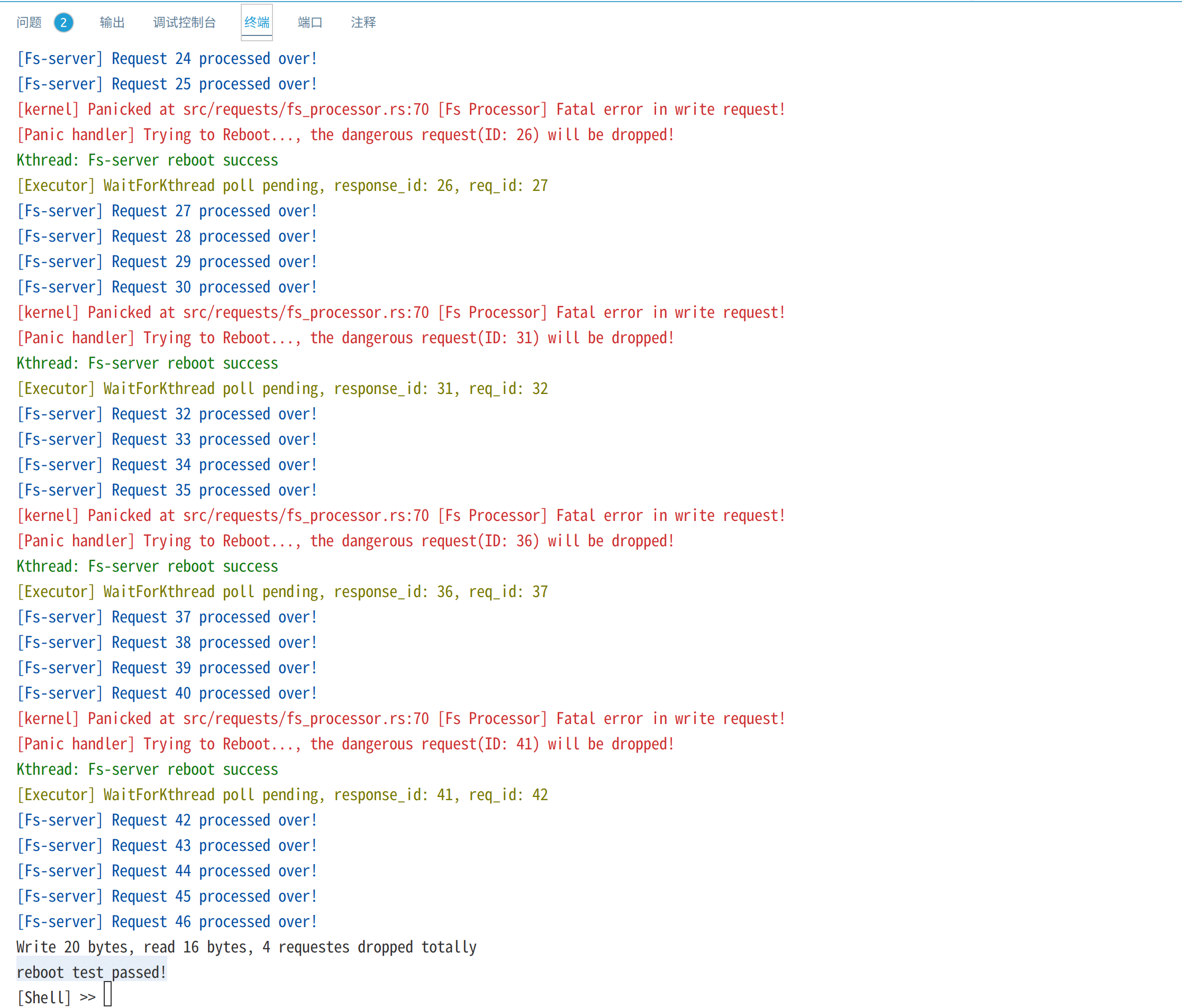
截图如下:
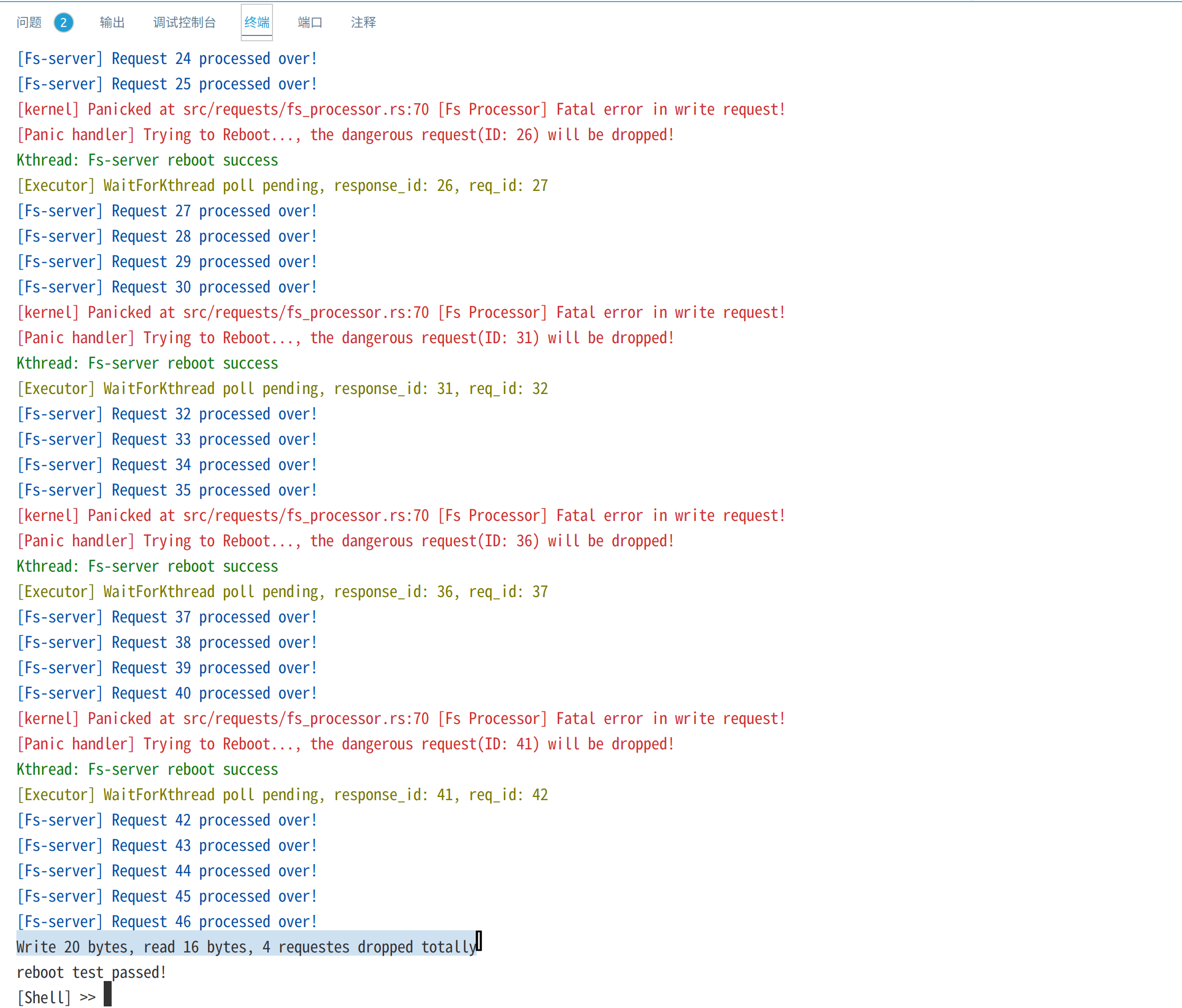
上图红色部分是文件系统内核线程触发的panic错误信息,绿色部分表示内核成功重启了文件系统内核线程,最终20次写请求有16个成功而4个请求重启后被丢弃,最终读出16个字节。
Shell重定向
类似Linux,使用 > 和 < 来重定向输入输出,下面的测试创建printargs进程且将输出重定向到file1,再使用cat读取file1中的内容。printargs简单地将所有命令行参数输出:
Shell管道
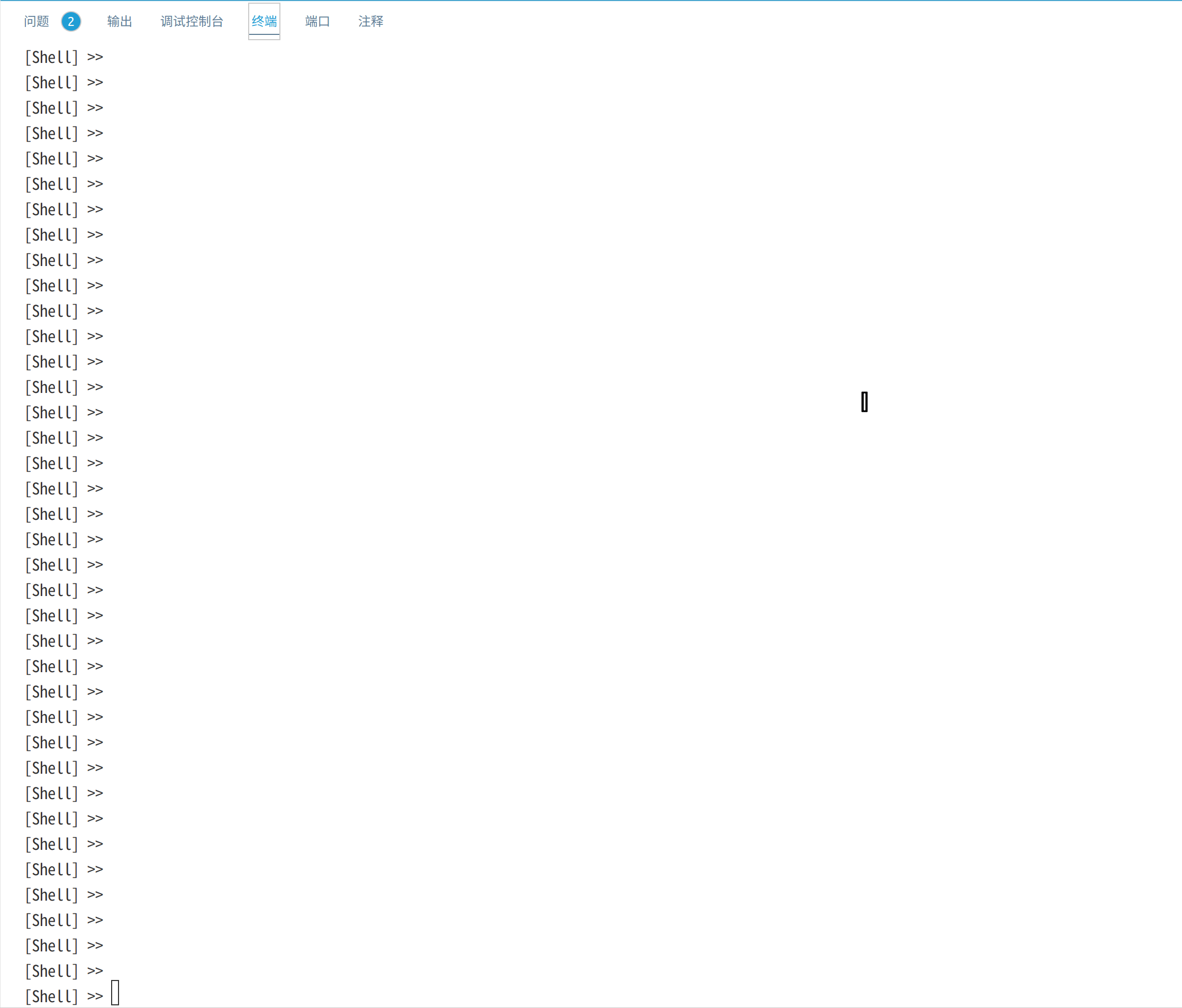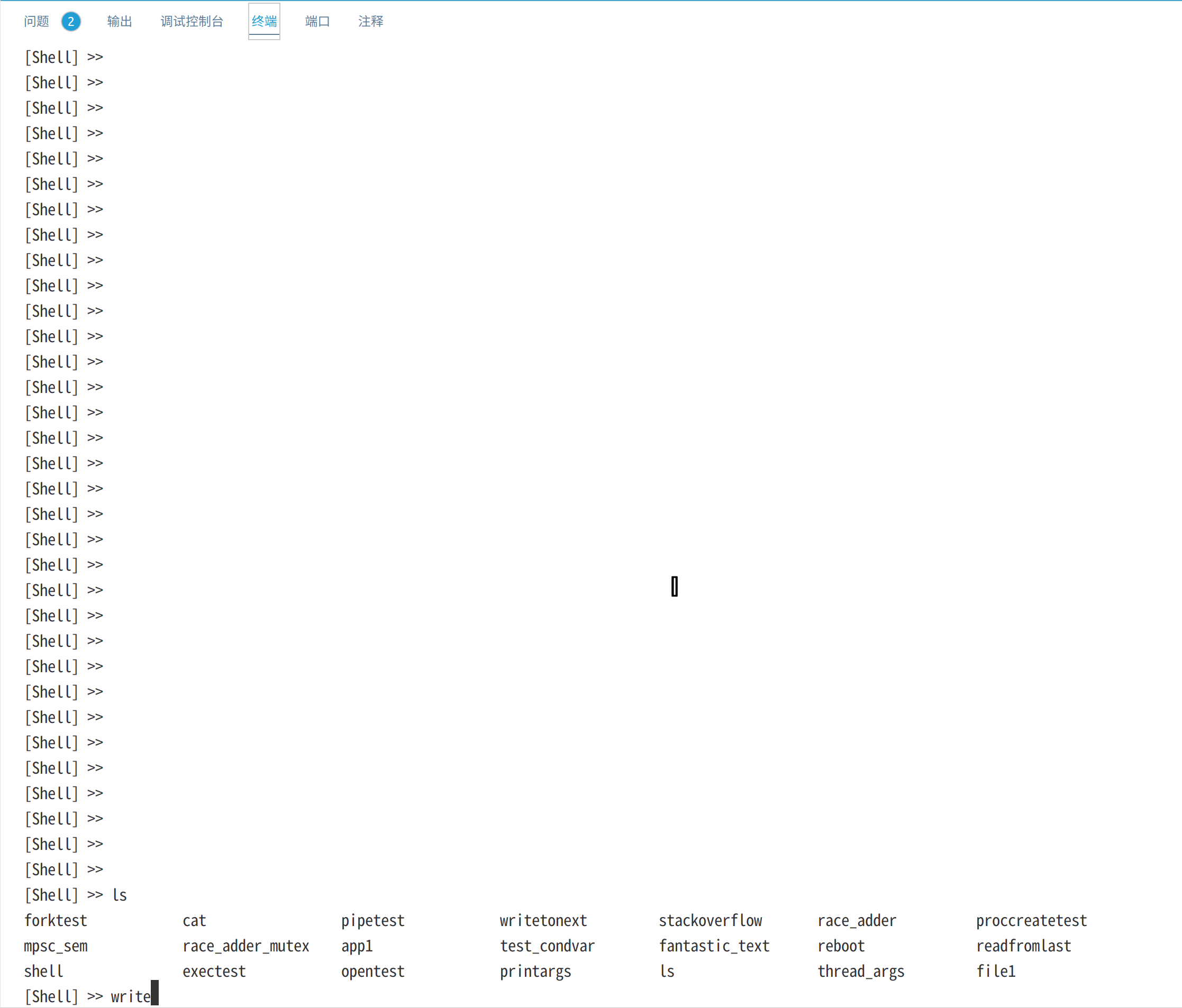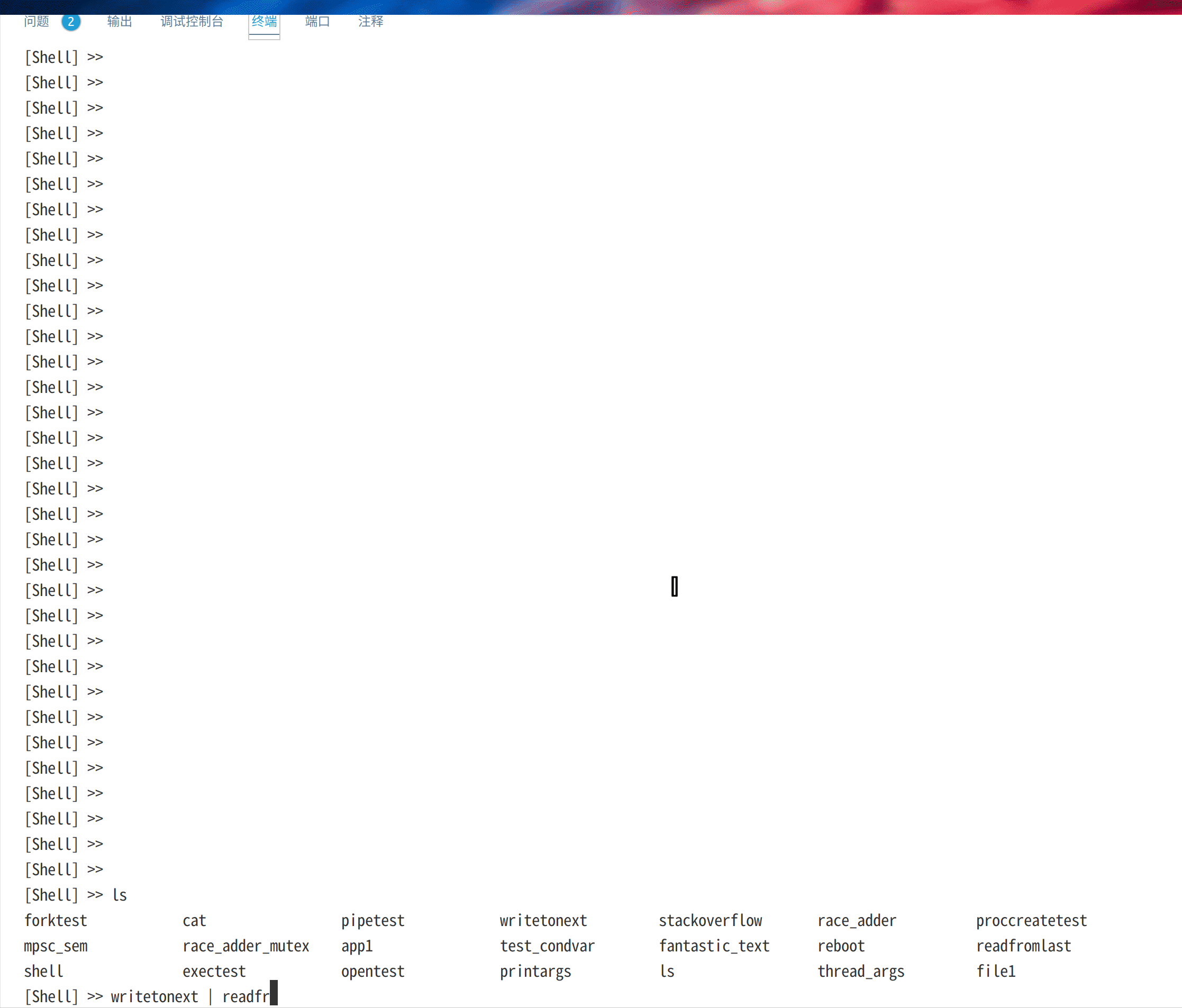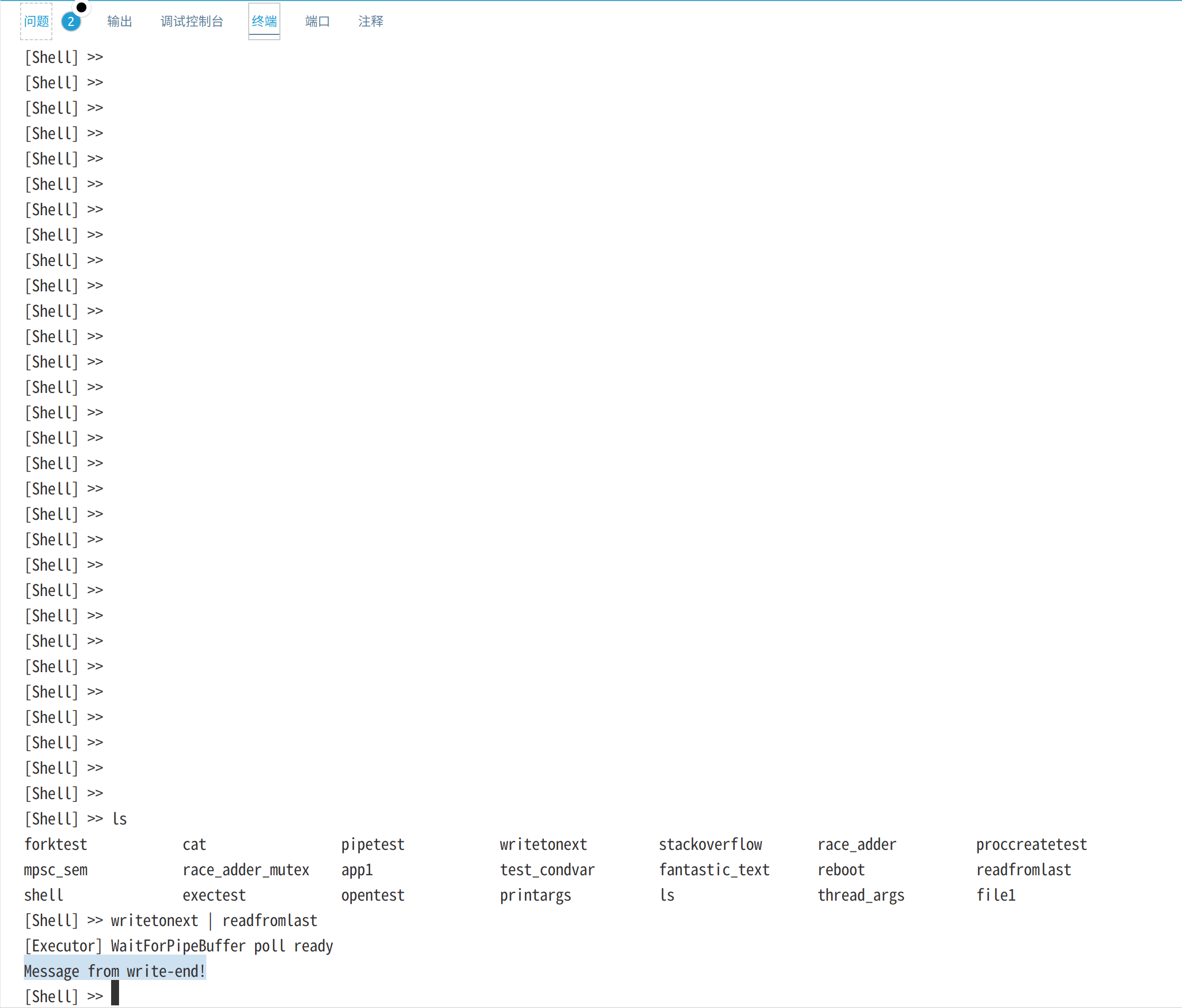
类似Linux,使用 | 将上一个进程的输出通过管道输送给下一个进程,下面的测试使用writetonext进程写字符串"Message from write-end!"到管道,再由进程readfromlast进程从管道读取并输出到终端:
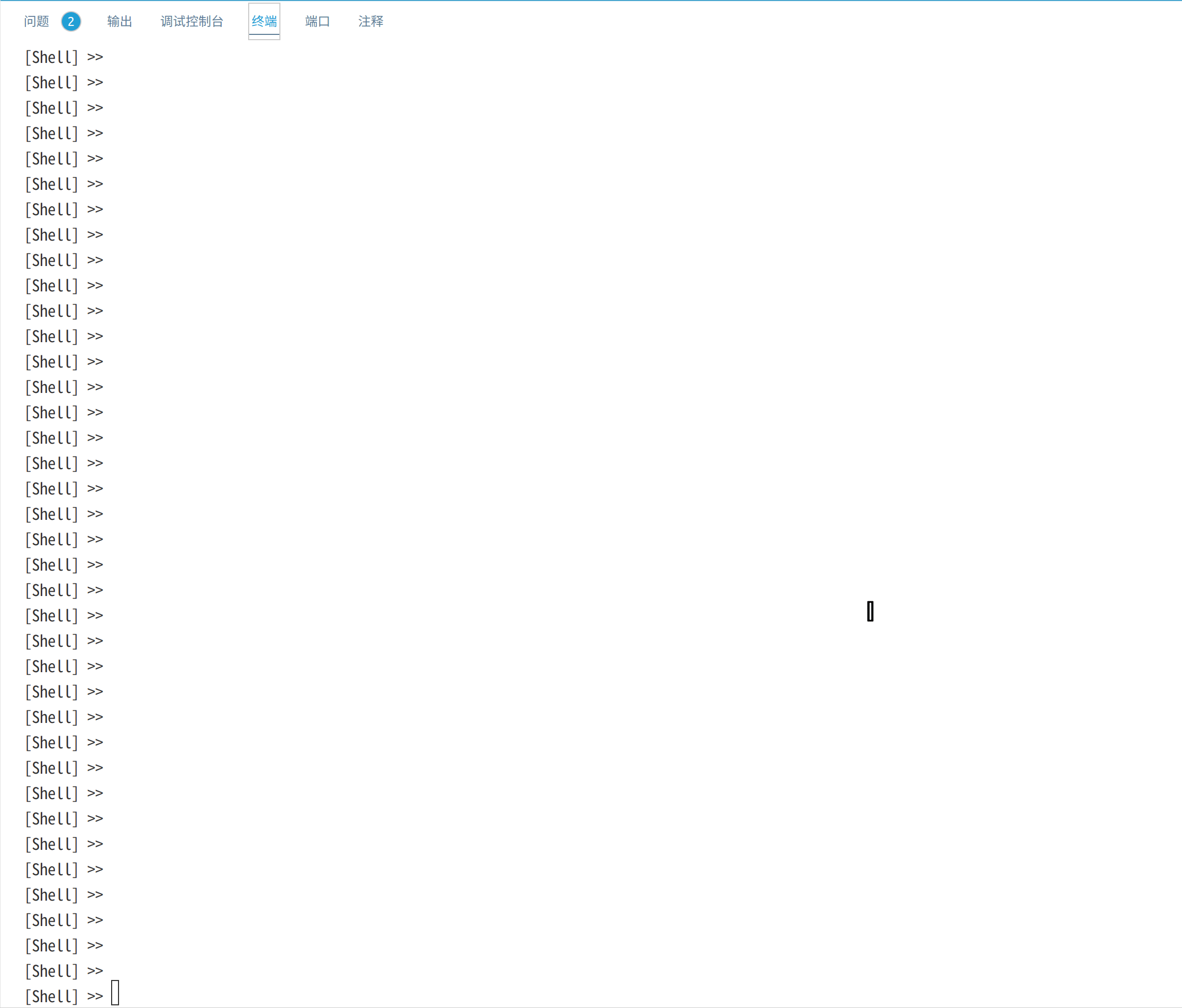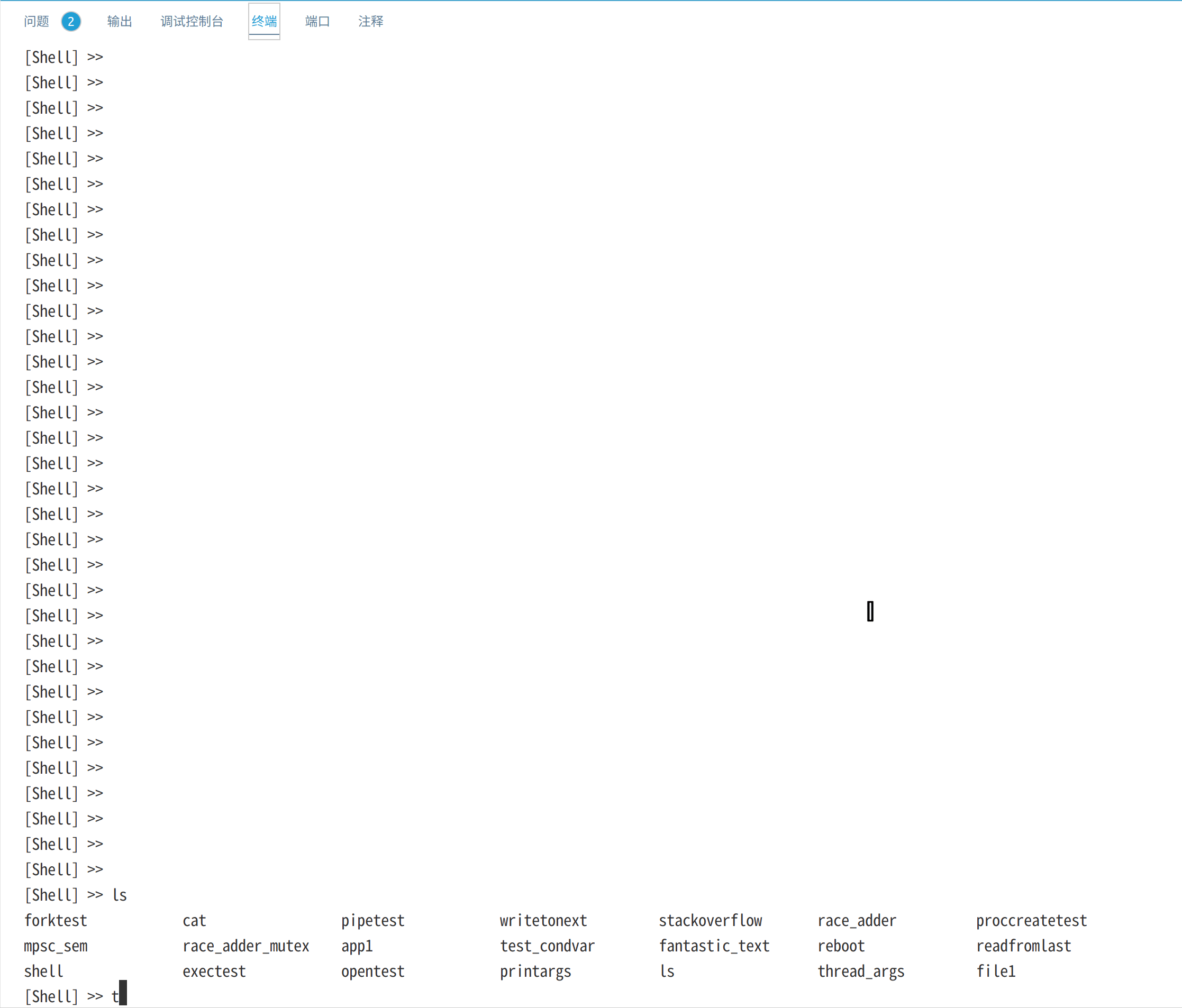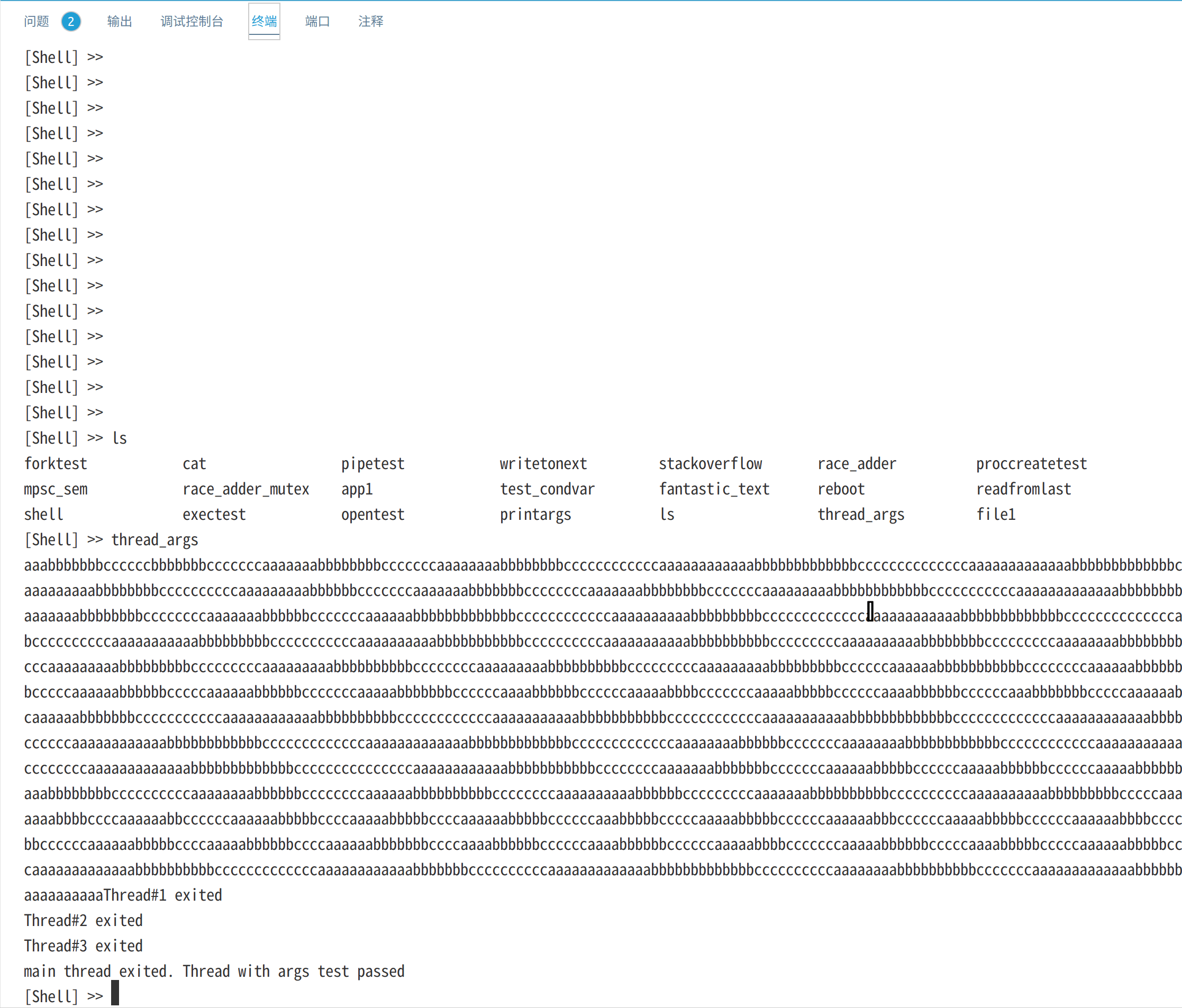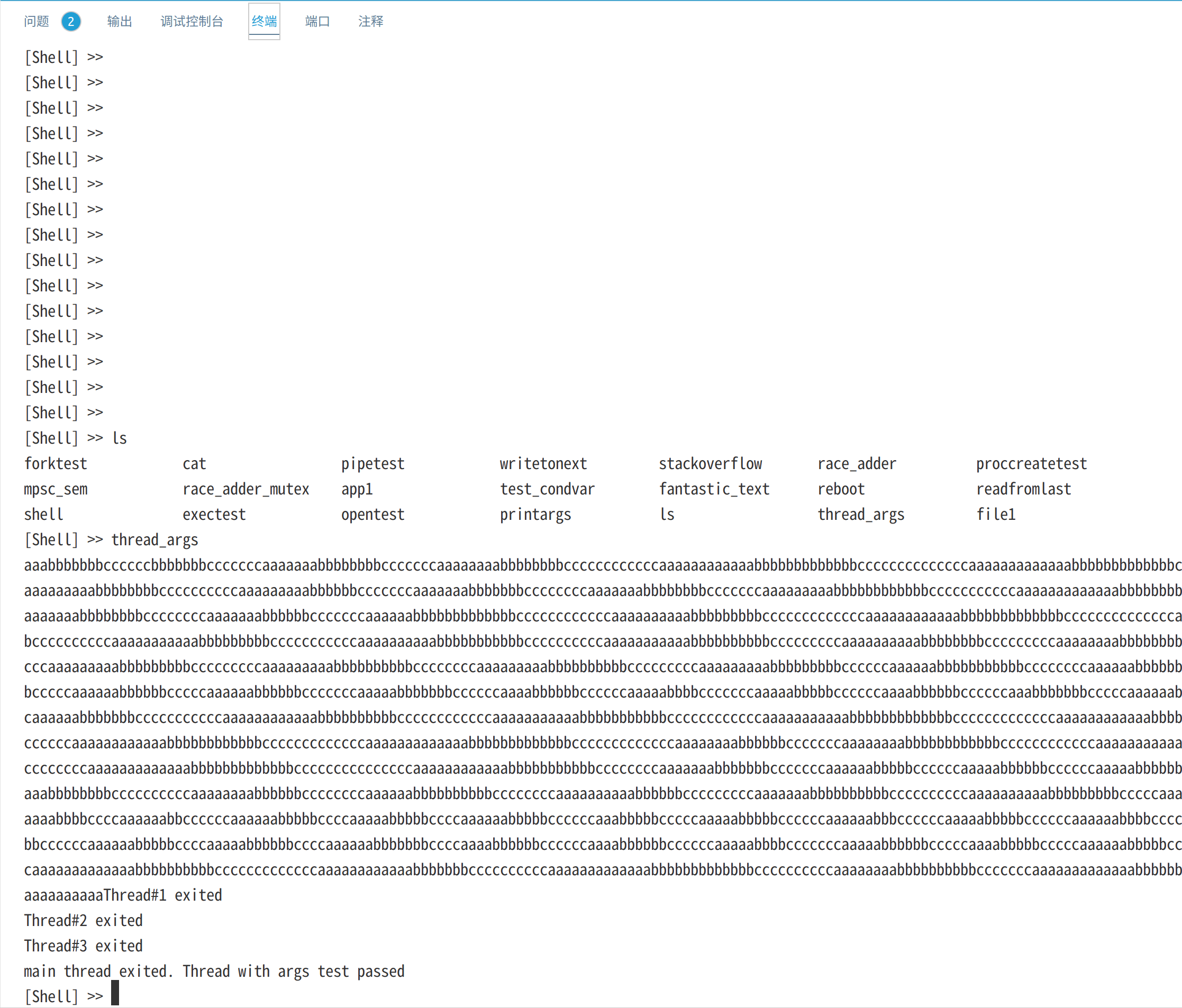
内核带参数多线程
thread_args程序创建三个线程,每个线程打印1000个a,b或c。
内核并发同步原语
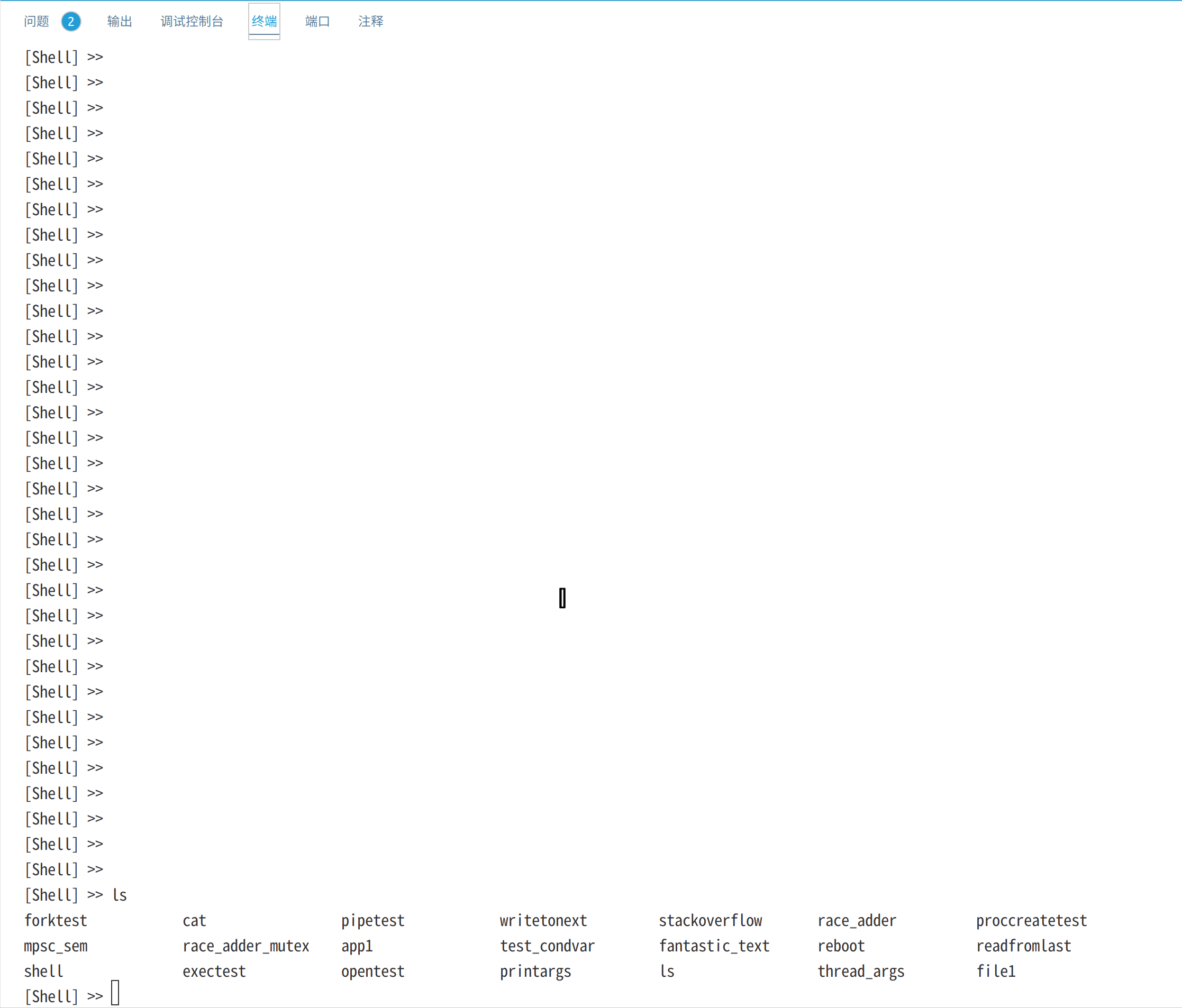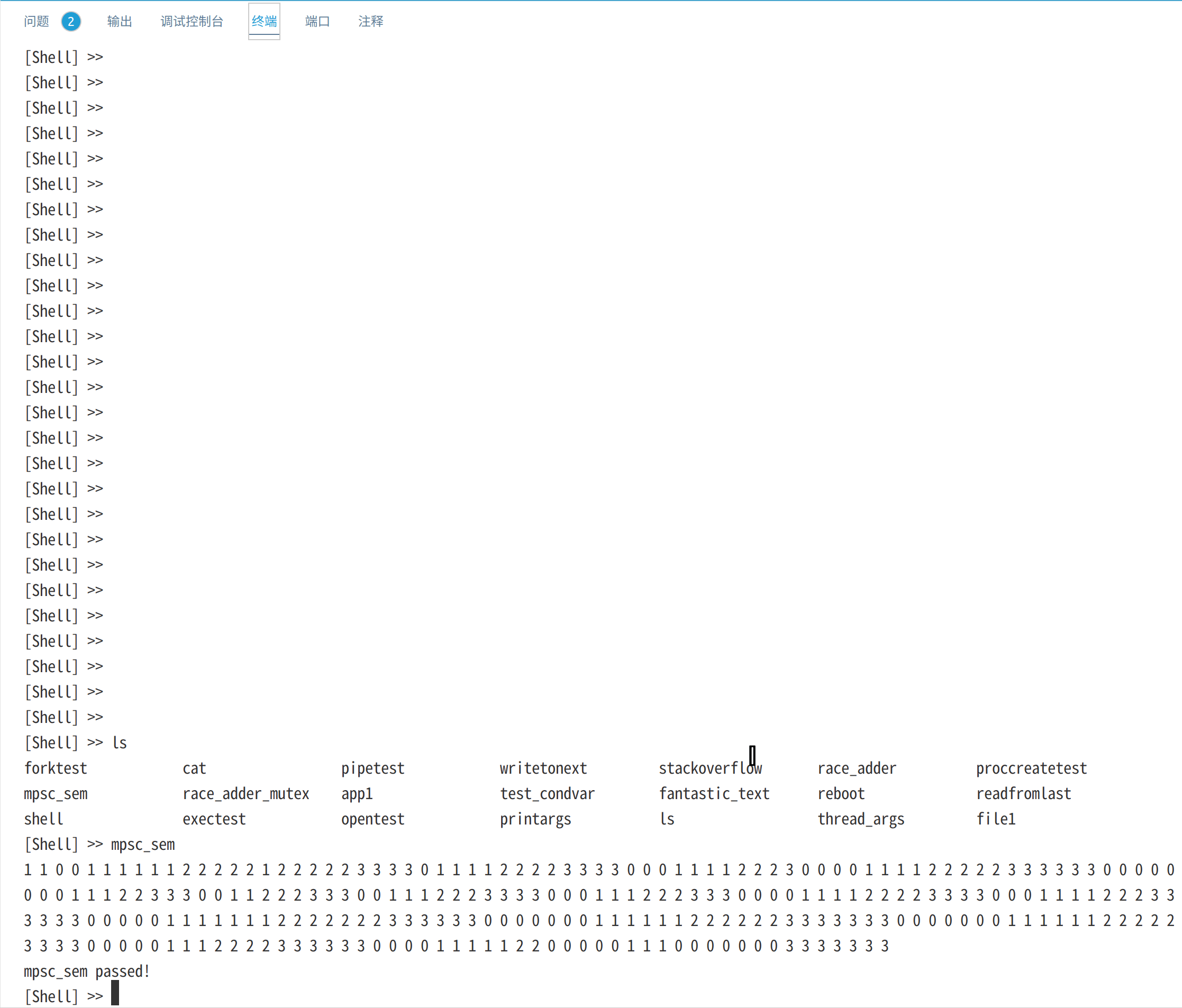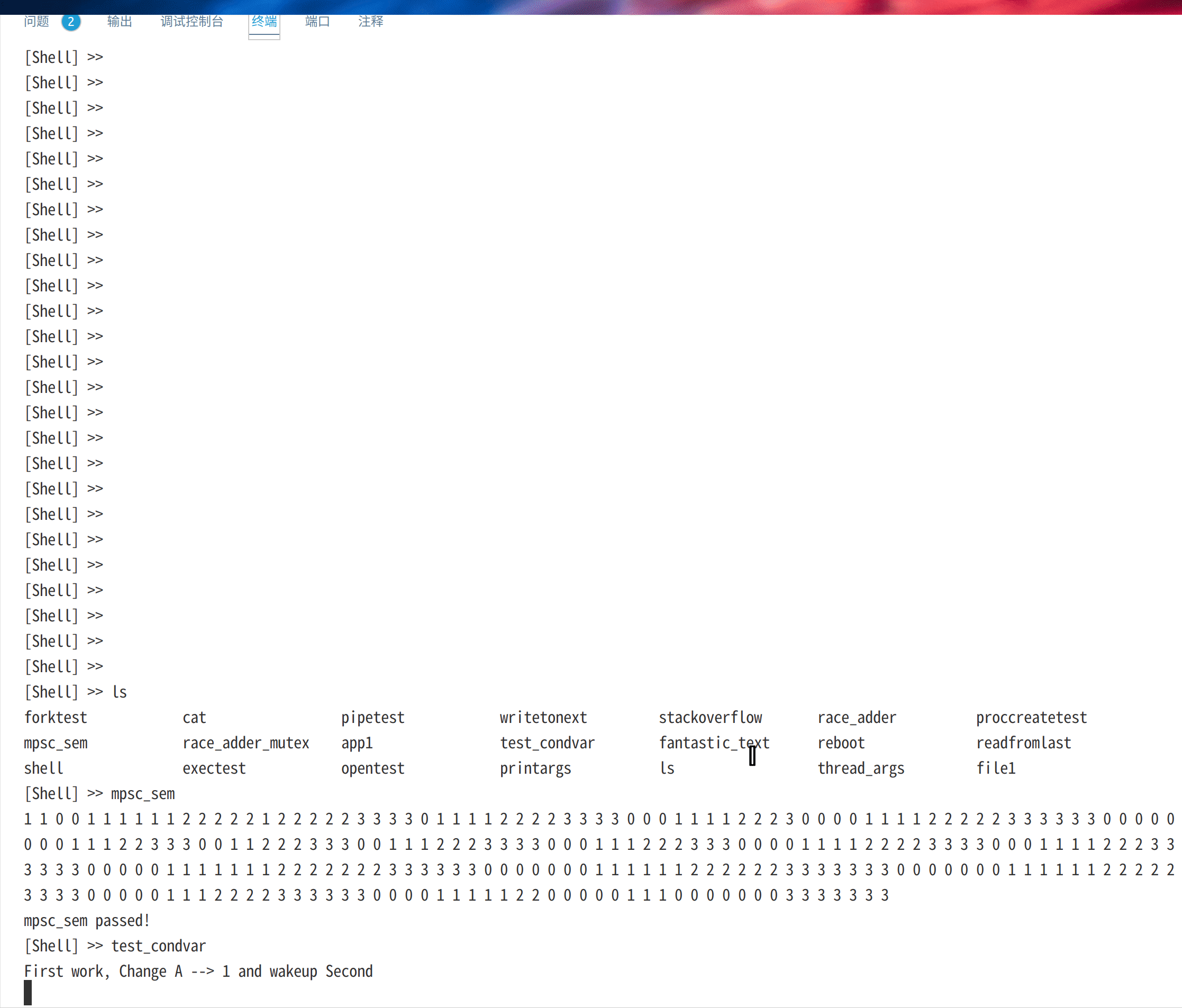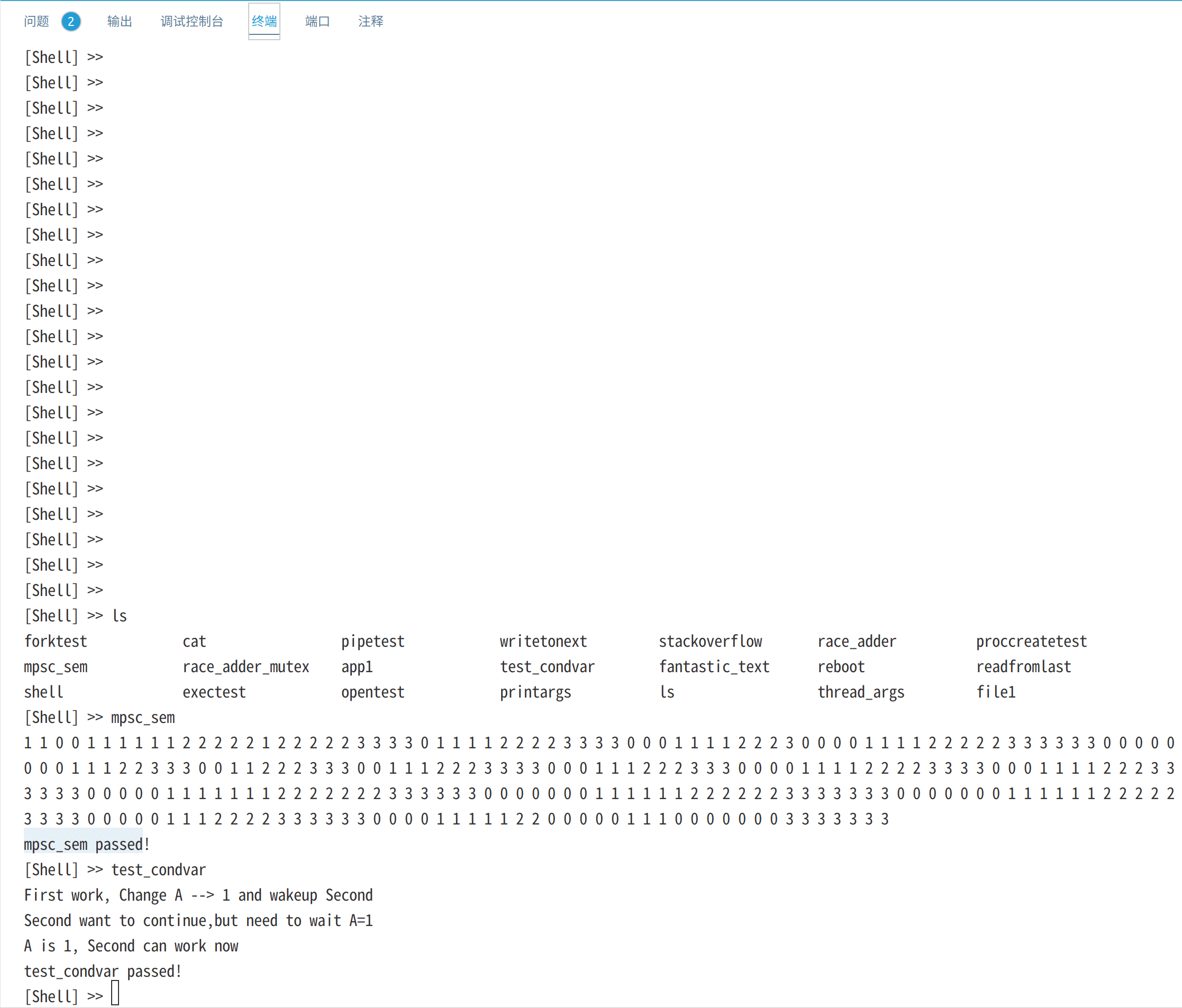
mpsc_sem是生产者消费者问题,测试内核中的信号量和互斥锁,而condvar_test测试内核条件变量。
总结与计划
nCore目前支持x86_64架构,实现了大约40个Linux系统调用,实现了宏内核与混合内核两种运行模式(编译时确定),支持musl-libc和原生Linux应用程序,正在逐步完成对于busybox和sqlite3等应用程序的支持。
计划
- 添加多核支持
- 添加更多内核线程
- 添加C语言用户程序支持
- 添加更多设备驱动